volatile
volatile
volatile是一個類型修飾符(type specifier).volatile的作用是作為指令關鍵字,確保本條指令不會因編譯器的優化而省略,且要求每次直接讀值。
volatile的變數是說這變數可能會被意想不到地改變,這樣,編譯器就不會去假設這個變數的值了。
簡單地說就是防止編譯器對代碼進行優化。比如如下程序:
1 2 3 4 | XBYTE[2]=0x55; XBYTE[2]=0x56; XBYTE[2]=0x57; XBYTE[2]=0x58; |
對外部硬體而言,上述四條語句分別表示不同的操作,會產生四種不同的動作,但是編譯器卻會對上述四條語句進行優化,認為只有XBYTE=0x58(即忽略前三條語句,只產生一條機器代碼)。如果鍵入 volatile,則編譯器會逐一地進行編譯併產生相應的機器代碼(產生四條代碼)。
精確地說就是,編譯器在用到這個變數時必須每次都小心地重新讀取這個變數的值,而不是使用保存在寄存器里的備份。下面是volatile變數的幾個例子:
1)并行設備的硬體寄存器(如:狀態寄存器)
2)一個中斷服務子程序中會訪問到的非自動變數(Non-automatic variables)
3)多線程應用中被幾個任務共享的變數
這是區分C程序員和嵌入式系統程序員的最基本的問題:嵌入式系統程序員經常同硬體、中斷、RTOS等等打交道,所有這些都要求使用volatile變數。不懂得volatile內容將會帶來災難。
假設被面試者正確地回答了這個問題(嗯,懷疑是否會是這樣),我將稍微深究一下,看一下這傢伙是不是真正懂得volatile完全的重要性。
1)一個參數既可以是const還可以是volatile嗎?解釋為什麼。
2)一個指針可以是volatile 嗎?解釋為什麼。
3)下面的函數被用來計算某個整數的平方,它能實現預期設計目標嗎?如果不能,試回答存在什麼問題:
1 2 3 4 | int square(volatile int *ptr) { return ((*ptr) * (*ptr)); } |
下面是答案:
1)是的。一個例子是只讀的狀態寄存器。它是volatile因為它可能被意想不到地改變。它是const因為程序不應該試圖去修改它。
2)是的。儘管這並不很常見。一個例子是當一個中斷服務子程序修改一個指向一個buffer的指針時。
3)這段代碼是個惡作劇。這段代碼的目的是用來返指針*ptr指向值的平方,但是,由於*ptr指向一個volatile型參數,編譯器將產生類似下面的代碼:
由於*ptr的值可能在兩次取值語句之間發生改變,因此a和b可能是不同的。結果,這段代碼可能返回的不是你所期望的平方值!正確的代碼如下:
講講個人理解:
關鍵在於兩個地方:
⒈編譯器的優化(請高手幫我看看下面的理解)
在本次線程內,當讀取一個變數時,為提高存取速度,編譯器優化時有時會先把變數讀取到一個寄存器中;以後再取變數值時,就直接從寄存器中取值;
當變數值在本線程里改變時,會同時把變數的新值copy到該寄存器中,以便保持一致
當變數在因別的線程等而改變了值,該寄存器的值不會相應改變,從而造成應用程序讀取的值和實際的變數值不一致
當該寄存器在因別的線程等而改變了值,原變數的值不會改變,從而造成應用程序讀取的值和實際的變數值不一致
舉一個不太準確的例子:
發薪資時,會計每次都把員工叫來登記他們的銀行卡號;一次會計為了省事,沒有即時登記,用了以前登記的銀行卡號;剛好一個員工的銀行卡丟了,已掛失該銀行卡號;從而造成該員工領不到工資
員工 -- 原始變數地址
銀行卡號 -- 原始變數在寄存器的備份
⒉ 在什麼情況下會出現
1)并行設備的硬體寄存器
2)一個中斷服務子程序中會訪問到的非自動變數(Non-automatic variables)
3)多線程應用中被幾個任務共享的變數
補充:volatile應該解釋為“直接存取原始內存地址”比較合適,“易變的”這種解釋簡直有點誤導人;
“易變”是因為外在因素引起的,像多線程,中斷等,並不是因為用volatile修飾了的變數就是“易變”了,假如沒有外因,即使用volatile定義,它也不會變化;
而用volatile定義之後,其實這個變數就不會因外因而變化了,可以放心使用了;大家看看前面那種解釋(易變的)是不是在誤導人
volatile關鍵字是一種類型修飾符,用它聲明的類型變數表示不可以被某些編譯器未知的因素更改,比如:操作系統、硬體或者其它線程等。遇到這個關鍵字聲明的變數,編譯器對訪問該變數的代碼就不再進行優化,從而可以提供對特殊地址的穩定訪問。
使用該關鍵字的例子如下:
當要求使用volatile 聲明的變數的值的時候,系統總是重新從它所在的內存讀取數據,即使它前面的指令剛剛從該處讀取過數據。而且讀取的數據立刻被保存。
例如:
//其他代碼,並未明確告訴編譯器,對i進行過操作
volatile 指出 i是隨時可能發生變化的,每次使用它的時候必須從i的地址中讀取,因而編譯器生成的彙編代碼會重新從i的地址讀取數據放在b中。而優化做法是,由於編譯器發現兩次從i讀數據的代碼之間的代碼沒有對i進行過操作,它會自動把上次讀的數據放在b中。而不是重新從i裡面讀。這樣一來,如果i是一個寄存器變數或者表示一個埠數據就容易出錯,所以說volatile可以保證對特殊地址的穩定訪問。
注意,在vc6中,一般調試模式沒有進行代碼優化,所以這個關鍵字的作用看不出來。下面通過插入彙編代碼,測試有無volatile關鍵字,對程序最終代碼的影響:
首先,用classwizard建一個win32 console工程,插入一個voltest.cpp文件,輸入下面的代碼:
然後,在調試版本模式運行程序,輸出結果如下:
i = 10
i = 32
然後,在release版本模式運行程序,輸出結果如下:
i = 10
i = 10
輸出的結果明顯表明,release模式下,編譯器對代碼進行了優化,第二次沒有輸出正確的i值。下面,我們把 i的聲明加上volatile關鍵字,看看有什麼變化:
分別在調試版本和release版本運行程序,輸出都是:
i = 10
i = 32
這說明這個關鍵字發揮了它的作用!
------------------------------------
volatile對應的變數可能在你的程序本身不知道的情況下發生改變
比如多線程的程序,共同訪問的內存當中,多個程序都可以操縱這個變數
你自己的程序,是無法判定何時這個變數會發生變化
還比如,他和一個外部設備的某個狀態對應,當外部設備發生操作的時候,通過驅動程序和中斷事件,系統改變了這個變數的數值,而你的程序並不知道。
對於volatile類型的變數,系統每次用到他的時候都是直接從對應的內存當中提取,而不會利用cache當中的原有數值,以適應它的未知何時會發生的變化,系統對這種變數的處理不會做優化——顯然也是因為它的數值隨時都可能變化的情況。
典型的例子
這個語句用來測試空循環的速度的
但是編譯器肯定要把它優化掉,根本就不執行
如果你寫成
它就會執行了
volatile的本意是“易變的”
由於訪問寄存器的速度要快過RAM,所以編譯器一般都會作減少存取外部RAM的優化。比如:
程序的本意是希望ISR_2中斷產生時,在main當中調用dosomething函數,但是,由於編譯器判斷在main函數裡面沒有修改過i,因此
可能只執行一次對從i到某寄存器的讀操作,然後每次if判斷都只使用這個寄存器裡面的“i副本”,導致dosomething永遠也不會被調用。如果將變數加上volatile修飾,則編譯器保證對此變數的讀寫操作都不會被優化(肯定執行)。此例中i也應該如此說明。
一般說來,volatile用在如下的幾個地方:
1、中斷服務程序中修改的供其它程序檢測的變數需要加volatile;
2、多任務環境下各任務間共享的標誌應該加volatile;
3、存儲器映射的硬體寄存器通常也要加volatile說明,因為每次對它的讀寫都可能有不同意義;
另外,以上這幾種情況經常還要同時考慮數據的完整性(相互關聯的幾個標誌讀了一半被打斷了重寫),在1中可以通過關中斷來實現,2 中可以禁止任務調度,3中則只能依靠硬體的良好設計了。
下面我們來一個個說明。
考慮下面的代碼:
代碼:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | class Gadget { public: void Wait() { while(!flag_) { Sleep(1000);//sleeps for 1000milli seconds } } void Wakeup() { flag_=true; } //... bool flag_; }; |
假設編譯器發現Sleep(1000)是調用一個外部的庫函數,它不會改變成員變數flag_,那麼編譯器就可以斷定它可以把flag_緩存在寄存器中,以後可以訪問該寄存器來代替訪問較慢的主板上的內存。這對於單線程代碼來說是一個很好的優化,但是在現在這種情況下,它破壞了程序的正確性:當你調用了某個Gadget的Wait函數后,即使另一個線程調用了Wakeup,Wait還是會一直循環下去。這是因為flag_的改變沒有反映到緩存它的寄存器中去。編譯器的優化未免有點太……樂觀了。
在大多數情況下,把變數緩存在寄存器中是一個非常有價值的優化方法,如果不用的話很可惜。C和C++給你提供了顯式禁用這種緩存優化的機會。如果你聲明變數是使用了volatile修飾符,編譯器就不會把這個變數緩存在寄存器里——每次訪問都將去存取變數在內存中的實際位置。這樣你要對Gadget的Wait/Wakeup做的修改就是給flag_加上正確的修飾:
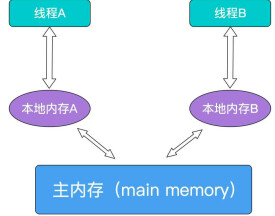
在當前的Java內存模型下,線程可以把變數保存在本地內存(比如機器的寄存器)中,而不是直接在主存中進行讀寫。這就可能造成一個線程在主存中修改了一個變數的值,而另外一個線程還繼續使用它在寄存器中的變數值的拷貝,造成數據的不一致。
要解決這個問題,只需要像在本程序中的這樣,把該變數聲明為volatile(不穩定的)即可,這就指示JVM,這個變數是不穩定的,每次使用它都到主存中進行讀取。一般說來,多任務環境下各任務間共享的標誌都應該加volatile修飾。
Volatile修飾的成員變數在每次被線程訪問時,都強迫從共享內存中重讀該成員變數的值。而且,當成員變數發生變化時,強迫線程將變化值回寫到共享內存。這樣在任何時刻,兩個不同的線程總是看到某個成員變數的同一個值。
Java語言規範中指出:為了獲得最佳速度,允許線程保存共享成員變數的私有拷貝,而且只當線程進入或者離開同步代碼塊時才與共享成員變數的原始值對比。
這樣當多個線程同時與某個對象交互時,就必須要注意到要讓線程及時的得到共享成員變數的變化。
而volatile關鍵字就是提示JVM:對於這個成員變數不能保存它的私有拷貝,而應直接與共享成員變數交互。
使用建議:在兩個或者更多的線程訪問的成員變數上使用volatile。當要訪問的變數已在synchronized代碼塊中,或者為常量時,不必使用。
由於使用volatile屏蔽掉了JVM中必要的代碼優化,所以在效率上比較低,因此一定在必要時才使用此關鍵字。
Java 語言包含兩種內在的同步機制:同步塊(或方法)和 volatile 變數。這兩種機制的提出都是為了實現代碼線程的安全性。其中 Volatile變數的同步性較差(但有時它更簡單並且開銷更低),而且其使用也更容易出錯。在這期的Java 理論與實踐中,Brian Goetz 將介紹幾種正確使用 volatile變數的模式,並針對其適用性限制提出一些建議。
Java 語言中的 volatile變數可以被看作是一種“程度較輕的 synchronized”;與 synchronized 塊相比,volatile 變數所需的編碼較少,並且運行時開銷也較少,但是它所能實現的功能也僅是 synchronized 的一部分。本文介紹了幾種有效使用 volatile變數的模式,並強調了幾種不適合使用 volatile 變數的情形。
鎖提供了兩種主要特性:互斥(mutual exclusion)和可見性(visibility)。互斥即一次只允許一個線程持有某個特定的鎖,因此可使用該特性實現對共享數據的協調訪問協議,這樣,一次就只有一個線程能夠使用該共享數據。可見性要更加複雜一些,它必須確保釋放鎖之前對共享數據做出的更改對於隨後獲得該鎖的另一個線程是可見的 —— 如果沒有同步機制提供的這種可見性保證,線程看到的共享變數可能是修改前的值或不一致的值,這將引發許多嚴重問題。
Volatile變數具有 synchronized 的可見性特性,但是不具備原子特性。這就是說線程能夠自動發現 volatile變數的最新值。Volatile變數可用於提供線程安全,但是只能應用於非常有限的一組用例:多個變數之間或者某個變數的當前值與修改後值之間沒有約束。因此,單獨使用 volatile 還不足以實現計數器、互斥鎖或任何具有與多個變數相關的不變式(Invariants)的類(例如“start <=end”)。
出於簡易性或可伸縮性的考慮,您可能傾向於使用 volatile變數而不是鎖。當使用 volatile變數而非鎖時,某些習慣用法(idiom)更加易於編碼和閱讀。此外,volatile變數不會像鎖那樣造成線程阻塞,因此也很少造成可伸縮性問題。在某些情況下,如果讀操作遠遠大於寫操作,volatile變數還可以提供優於鎖的性能優勢。
正確使用 volatile 變數的條件
您只能在有限的一些情形下使用 volatile變數替代鎖。要使 volatile變數提供理想的線程安全,必須同時滿足下面兩個條件:
● 對變數的寫操作不依賴於當前值。
● 該變數沒有包含在具有其他變數的不變式中。
實際上,這些條件表明,可以被寫入 volatile變數的這些有效值獨立於任何程序的狀態,包括變數的當前狀態。
第一個條件的限制使 volatile變數不能用作線程安全計數器。雖然增量操作(x++)看上去類似一個單獨操作,實際上它是一個由讀取-修改-寫入操作序列組成的組合操作,必須以原子方式執行,而 volatile 不能提供必須的原子特性。實現正確的操作需要使 x 的值在操作期間保持不變,而 volatile變數無法實現這點。(然而,如果將值調整為只從單個線程寫入,那麼可以忽略第一個條件。)
大多數編程情形都會與這兩個條件的其中之一衝突,使得 volatile變數不能像 synchronized 那樣普遍適用於實現線程安全。清單 1 顯示了一個非線程安全的數值範圍類。它包含了一個不變式 —— 下界總是小於或等於上界。
清單 1. 非線程安全的數值範圍類
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | @NotThreadSafe public class NumberRange{ private int lower,upper; public int getLower(){ return lower; } public int getUpper(){ return upper; } public void setLower(int value){ if(value > upper) throw new IllegalArgumentException(...); lower = value; } public void setUpper(int value){ if(value < lower) throw new IllegalArgumentException(...); upper = value; } } |
這種方式限制了範圍的狀態變數,因此將 lower 和 upper 欄位定義為 volatile 類型不能夠充分實現類的線程安全;從而仍然需要使用同步。否則,如果湊巧兩個線程在同一時間使用不一致的值執行 setLower 和 setUpper 的話,則會使範圍處於不一致的狀態。例如,如果初始狀態是 (0,5),同一時間內,線程 A 調用 setLower⑷ 並且線程 B 調用 setUpper⑶,顯然這兩個操作交叉存入的值是不符合條件的,那麼兩個線程都會通過用於保護不變式的檢查,使得最後的範圍值是(4,3) —— 一個無效值。至於針對範圍的其他操作,我們需要使 setLower() 和 setUpper() 操作原子化 —— 而將欄位定義為 volatile 類型是無法實現這一目的的。
性能考慮
使用 volatile變數的主要原因是其簡易性:在某些情形下,使用 volatile 變數要比使用相應的鎖簡單得多。使用 volatile變數次要原因是其性能:某些情況下,volatile 變數同步機制的性能要優於鎖。
很難做出準確、全面的評價,例如“X 總是比 Y 快”,尤其是對 JJVM 內在的操作而言。(例如,某些情況下 JVM 也許能夠完全刪除鎖機制,這使得我們難以抽象地比較 volatile和 synchronized 的開銷。)就是說,在目前大多數的處理器架構上,volatile 讀操作開銷非常低 —— 幾乎和非 volatile 讀操作一樣。而 volatile 寫操作的開銷要比非 volatile 寫操作多很多,因為要保證可見性需要實現內存界定(Memory Fence),即便如此,volatile 的總開銷仍然要比鎖獲取低。
volatile 操作不會像鎖一樣造成阻塞,因此,在能夠安全使用 volatile 的情況下,volatile 可以提供一些優於鎖的可伸縮特性。如果讀操作的次數要遠遠超過寫操作,與鎖相比,volatile變數通常能夠減少同步的性能開銷。
正確使用 volatile 的模式
很多併發性專家事實上往往引導用戶遠離 volatile變數,因為使用它們要比使用鎖更加容易出錯。然而,如果謹慎地遵循一些良好定義的模式,就能夠在很多場合內安全地使用 volatile 變數。要始終牢記使用 volatile 的限制 —— 只有在狀態真正獨立於程序內其他內容時才能使用 volatile —— 這條規則能夠避免將這些模式擴展到不安全的用例。
模式 #1:狀態標誌也許實現 volatile 變數的規範使用僅僅是使用一個布爾狀態標誌,用於指示發生了一個重要的一次性事件,例如完成初始化或請求停機。
很多應用程序包含了一種控制結構,形式為“在還沒有準備好停止程序時再執行一些工作”,如清單 2 所示:
清單 2. 將 volatile變數作為狀態標誌使用
很可能會從循環外部調用 shutdown() 方法 —— 即在另一個線程中 —— 因此,需要執行某種同步來確保正確實現 shutdownRequested 變數的可見性。(可能會從 JMX 偵聽程序、GUI 事件線程中的操作偵聽程序、通過 RMI 、通過一個 Web 服務等調用)。然而,使用 synchronized 塊編寫循環要比使用清單 2 所示的 volatile狀態標誌編寫麻煩很多。由於 volatile 簡化了編碼,並且狀態標誌並不依賴於程序內任何其他狀態,因此此處非常適合使用 volatile。
這種類型的狀態標記的一個公共特性是:通常只有一種狀態轉換;shutdownRequested 標誌從 false 轉換為 true,然後程序停止。這種模式可以擴展到來迴轉換的狀態標誌,但是只有在轉換周期不被察覺的情況下才能擴展(從 false 到 true,再轉換到 false)。此外,還需要某些原子狀態轉換機制,例如原子變數。
模式 #2:一次性安全發布(one-time safe publication)
缺乏同步會導致無法實現可見性,這使得確定何時寫入對象引用而不是原語值變得更加困難。在缺乏同步的情況下,可能會遇到某個對象引用的更新值(由另一個線程寫入)和該對象狀態的舊值同時存在。(這就是造成著名的雙重檢查鎖定(double-checked-locking)問題的根源,其中對象引用在沒有同步的情況下進行讀操作,產生的問題是您可能會看到一個更新的引用,但是仍然會通過該引用看到不完全構造的對象)。
實現安全發布對象的一種技術就是將對象引用定義為 volatile 類型。清單 3 展示了一個示例,其中後台線程在啟動階段從資料庫載入一些數據。其他代碼在能夠利用這些數據時,在使用之前將檢查這些數據是否曾經發布過。
清單 3. 將 volatile變數用於一次性安全發布
如果 theFlooble 引用不是 volatile 類型,doWork() 中的代碼在解除對 theFlooble 的引用時,將會得到一個不完全構造的 Flooble。
該模式的一個必要條件是:被發布的對象必須是線程安全的,或者是有效的不可變對象(有效不可變意味著對象的狀態在發布之後永遠不會被修改)。volatile 類型的引用可以確保對象的發布形式的可見性,但是如果對象的狀態在發布后將發生更改,那麼就需要額外的同步。
模式 #3:獨立觀察(independent observation)
安全使用 volatile 的另一種簡單模式是:定期“發布”觀察結果供程序內部使用。例如,假設有一種環境感測器能夠感覺環境溫度。一個後台線程可能會每隔幾秒讀取一次該感測器,並更新包含當前文檔的 volatile 變數。然後,其他線程可以讀取這個變數,從而隨時能夠看到最新的溫度值。
使用該模式的另一種應用程序就是收集程序的統計信息。清單 4 展示了身份驗證機制如何記憶最近一次登錄的用戶的名字。將反覆使用 lastUser 引用來發布值,以供程序的其他部分使用。
清單 4. 將 volatile變數用於多個獨立觀察結果的發布
該模式是前面模式的擴展;將某個值發布以在程序內的其他地方使用,但是與一次性事件的發布不同,這是一系列獨立事件。這個模式要求被發布的值是有效不可變的 —— 即值的狀態在發布后不會更改。使用該值的代碼需要清楚該值可能隨時發生變化。
模式 #4:“volatile bean”模式
volatile bean 模式適用於將 JavaBeans 作為“榮譽結構”使用的框架。在 volatile bean 模式中,JavaBean 被用作一組具有 getter 和/或 setter 方法 的獨立屬性的容器。volatile bean 模式的基本原理是:很多框架為易變數據的持有者(例如 HttpSession)提供了容器,但是放入這些容器中的對象必須是線程安全的。
在 volatile bean 模式中,JavaBean 的所有數據成員都是 volatile 類型的,並且 getter 和 setter 方法必須非常普通 —— 除了獲取或設置相應的屬性外,不能包含任何邏輯。此外,對於對象引用的數據成員,引用的對象必須是有效不可變的。(這將禁止具有數組值的屬性,因為當數組引用被聲明為 volatile 時,只有引用而不是數組本身具有 volatile 語義)。對於任何 volatile變數,不變式或約束都不能包含 JavaBean 屬性。清單 5 中的示例展示了遵守 volatile bean 模式的 JavaBean:
清單 5. 遵守 volatile bean 模式的 Person 對象
volatile 的高級模式
前面幾節介紹的模式涵蓋了大部分的基本用例,在這些模式中使用 volatile 非常有用並且簡單。這一節將介紹一種更加高級的模式,在該模式中,volatile 將提供性能或可伸縮性優勢。
volatile 應用的的高級模式非常脆弱。因此,必須對假設的條件仔細證明,並且這些模式被嚴格地封裝了起來,因為即使非常小的更改也會損壞您的代碼!同樣,使用更高級的 volatile 用例的原因是它能夠提升性能,確保在開始應用高級模式之前,真正確定需要實現這種性能獲益。需要對這些模式進行權衡,放棄可讀性或可維護性來換取可能的性能收益 —— 如果您不需要提升性能(或者不能夠通過一個嚴格的測試程序證明您需要它),那麼這很可能是一次糟糕的交易,因為您很可能會得不償失,換來的東西要比放棄的東西價值更低。
模式 #5:開銷較低的讀-寫鎖策略
目前為止,您應該了解了 volatile 的功能還不足以實現計數器。因為 ++x 實際上是三種操作(讀、添加、存儲)的簡單組合,如果多個線程湊巧試圖同時對 volatile 計數器執行增量操作,那麼它的更新值有可能會丟失。
然而,如果讀操作遠遠超過寫操作,您可以結合使用內部鎖和 volatile變數來減少公共代碼路徑的開銷。清單 6 中顯示的線程安全的計數器使用 synchronized 確保增量操作是原子的,並使用 volatile 保證當前結果的可見性。如果更新不頻繁的話,該方法可實現更好的性能,因為讀路徑的開銷僅僅涉及 volatile 讀操作,這通常要優於一個無競爭的鎖獲取的開銷。
清單 6. 結合使用 volatile 和 synchronized 實現“開銷較低的讀-寫鎖”
之所以將這種技術稱之為“開銷較低的讀-寫鎖”是因為您使用了不同的同步機制進行讀寫操作。因為本例中的寫操作違反了使用 volatile 的第一個條件,因此不能使用 volatile 安全地實現計數器 —— 您必須使用鎖。然而,您可以在讀操作中使用 volatile 確保當前值的可見性,因此可以使用鎖進行所有變化的操作,使用 volatile 進行只讀操作。其中,鎖一次只允許一個線程訪問值,volatile 允許多個線程執行讀操作,因此當使用 volatile 保證讀代碼路徑時,要比使用鎖執行全部代碼路徑獲得更高的共享度 —— 就像讀-寫操作一樣。然而,要隨時牢記這種模式的弱點:如果超越了該模式的最基本應用,結合這兩個競爭的同步機制將變得非常困難。
結束語
與鎖相比,Volatile變數是一種非常簡單但同時又非常脆弱的同步機制,它在某些情況下將提供優於鎖的性能和伸縮性。如果嚴格遵循 volatile 的使用條件 —— 即變數真正獨立於其他變數和自己以前的值 —— 在某些情況下可以使用 volatile 代替 synchronized 來簡化代碼。然而,使用 volatile 的代碼往往比使用鎖的代碼更加容易出錯。本文介紹的模式涵蓋了可以使用 volatile 代替 synchronized 的最常見的一些用例。遵循這些模式(注意使用時不要超過各自的限制)可以幫助您安全地實現大多數用例,使用 volatile變數獲得更佳性能。
基本信息
- 中文名
- 易變型變數
- 外文名
- volatile
- 釋義
- 一個類型修飾符