卷積碼
1955年Elias等提出的編碼方法
卷積碼將k個信息比特編成n個比特,但k和n通常很小,特別適合以串列形式進行傳輸,時延小。
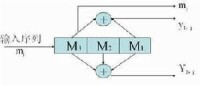
卷積碼的編碼器
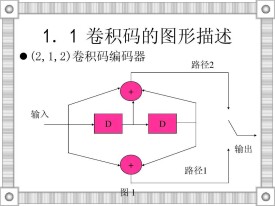
一種卷積碼編碼器
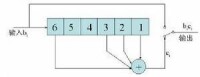
一種卷積碼編碼器
卷積碼和分組碼的根本區別在於,它不是把信息序列分組后再進行單獨編碼,而是由連續輸入的信息序列得到連續輸出的已編碼序列。即進行分組編碼時,其本組中的個校驗元僅與本組的k個信息元有關,而與其它各組信息無關;但在卷積碼中,其編碼器將k個信息碼元編為n個碼元時,這n個碼元不僅與當前段的k個信息有關,而且與前面的段信息有關(m為編碼的約束長度)。
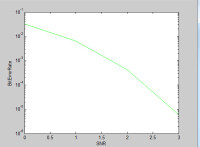
同樣,在卷積碼解碼過程中,不僅從此時刻收到的碼組中提取解碼信息,而且還要利用以前或以後各時刻收到的碼組中提取有關信息。而且卷積碼的糾錯能力隨約束長度的增加而增強,差錯率則隨著約束長度增加而呈指數下降。
狀態圖
卷積碼的糾錯能力不僅與約束長度有關,還與採用的解碼方式有關。總之,由於n,k較小,且利用了各組之間的相關性,在同樣的碼率和設備的複雜性條件下,無論理論上還是實踐上都證明:卷積碼的性能至少不比分組碼差。
卷積碼編碼器
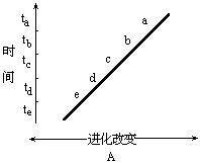
狀態圖2
矩陣圖
在一般情況下,輸入信息序列經過一個時分開關被分成k0個子序列,分別以u(x)表示,其中,即。編碼器的結構由k0×n0階生成多項式矩陣給定。輸出碼序列由n0個子序列組成,即。若m是所有子生成多項式g(x)中最高次式的次數,稱這種碼為卷積碼。
多項式法
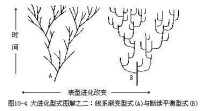
描述卷積碼編碼器過程的方法有很多,如矩陣法、多項式、碼樹和網格圖等,這裡我們主要介紹和卷積碼編碼器結構密切相關的多項式法,以及與卷積碼解碼密切相關的網格圖法。
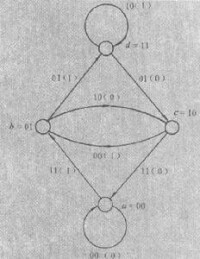
卷積碼狀態圖
結構圖
多項式法就是由卷積碼的生成多項式直接得出其編碼器的結構圖。如前面 例子中的卷積碼的生成多項式矩陣為:
其中,D是延遲運算元,生成多項式的第一項為1 D ,表示輸出編碼的第一個碼元等於輸入碼元與前兩個時刻輸入的碼元的模2和,同理第二項類似。
卷積碼
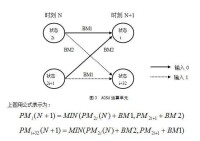
將編碼器寄存器中的內容組合定義為編碼器狀態。如仍以前面所舉的例子為例,則該編碼器的狀態有四種:00,10,01和11,下面分別用a,b,c,d來代替。編碼器在每一個時鐘沿打入一個輸入信息x(n),因此圖示寄存器組合內容就變為即狀態發生了轉移,並同時輸出G0(n)、G1(n)。由此我們可以將圖所示編碼過程用右圖所示的狀態圖表示。
編碼器

網格圖
網格圖
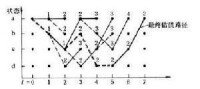
維特比解碼過程
寄存器
若通道干擾序列為,其中。接收序列為
其中和。這裡“+”為模 2 運算()。解碼就是根據編碼規則和通道干擾的統計特性,對信息序列作出估值的方法。常用的有三類解碼方法,即代數解碼、維特比解碼和序貫解碼。
⒈代數

衛星
⒉維特比
維特比解碼過程
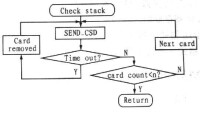
回溯法TB
維特比解碼器的複雜性隨m呈指數增大。實用中m不大於10。它在衛星和深空通信中有廣泛的應用。在解決碼間串擾和數據壓縮中也可應用。
⒊ 序貫解碼
序貫解碼是根據接收序列和編碼規則,在整個碼樹中搜索(既可以前進,也可以後退)出一條與接收序列距離(或其他量度)最小的一種演演算法。由於它的解碼器的複雜性隨m值增大而線性增長,在實用中可以選用較大的m值(如)以保證更高的可靠性。許多深空和海事通信系統都採用序貫解碼。
Viterbi 解碼示例
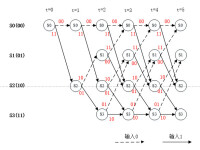
Viterbi 解碼示例
①根據接收碼符號R,計算出相應的分支量度值;
②進入某一狀態的2 條分支量度與其前狀態路徑量度PM累加求和;
③比較到達當前狀態的2 條新的路徑量度PM的大小,選擇最大者作為新的狀態路徑量度存儲起來,並保存與此路徑對應的碼字;
④對所有的256 個狀態都實施上述加、比、選(ACS) 運算;
⑤在每一解碼時刻,滿足延時就從256 條留存路徑中,選擇路徑量度最大的一條路徑作為解碼數據輸出;
⑥進入下一解碼時刻,重複以上步驟,直至解碼結束。
由於卷積碼解碼的複雜度隨著約束長度的增加以非線性方式迅速增加,在實際應用中,卷積碼的實際應用性能往往受限於存儲器容量和系統運算速度,尤其是對約束長度比較大的卷積碼。為了在有限的硬體或軟體資源條件下保證系統較高的解碼性能,下面對演演算法進行優化。
⒈ 留存路徑更新演演算法優化
傳統的實現留存路徑存儲器(SMU) 更新的演演算法,有寄存器交換法RE 和回溯法TB ,其詳細內容請參考有關文獻。寄存器交換法利用數據在寄存器中不斷交換,來更新留存路徑,實現信息的解碼,相對於TB 法不斷讀寫存儲數據和需要延時回溯判決,其優點是存儲單元少、解碼延時短。RE 方法的缺點是內聯關係過於複雜,不適合約束長度比較大的卷積碼解碼器的FPGA實現。基於RE 提出了對留存路徑存儲及輸出優化的實現方法,具體描述如下:.
具體描述
①逐狀態分配256 個存儲器單元,單元位數由延時D (解碼深度) 決定,每單元存儲一個碼字;
解碼深度
③每一個解碼時刻只向存儲單元中存人留存路徑的碼字,並把選定碼字寫入存儲單元中最低位;
④當解碼時刻大於延時D 時,判決出當前時刻的所有狀態中具有最大路徑量度的狀態,並將其對應的留存路徑存儲單元中的最高位作為解碼結果輸出;
⑤在實現存儲單元的移位時,可採用循環移位的方式,避免重複讀寫,在軟體實現時如果採用指針的方式讀寫地址,也可以做到只用一套存儲器,這樣就能繼續在節省空間和提高運算速度上更進一步,在Matlab模擬中由於系統本身的特點,只須用簡單的命令完成以上操作。
由於留存路徑存儲器中存入的只是路徑信息,因而節省了存儲空間;當解碼輸出時,只讀出具有最大路徑量度的狀態所對應的留存路徑存儲單元最高位即可,不須向前回溯,減少了讀RAM的次數(由D次減少至1 次)提高了解碼速度。
⒉優化判決
解碼深度圖
基本信息
- 中文名
- 卷積碼
- 外文名
- convolutional code
- 所屬技術
- 電信技術
- 提出
- 1955年