共找到2條詞條名為數據清洗的結果 展開
- 學術名詞
- 清華大學出版社2018年出版圖書
數據清洗
學術名詞
數據清洗是指發現並糾正數據文件中可識別的錯誤的最後一道程序,包括檢查數據一致性,處理無效值和缺失值等。與問卷審核不同,錄入后的數據清理一般是由計算機而不是人工完成。
據清洗( )– 據審查校驗程,刪除復息、糾存錯誤,提供據致。
據清洗“臟”“洗掉”,指糾據件識錯誤程序,包括檢查據致,效值缺值。據倉庫據某題據集合,據業務系統抽取且包含歷史據,避免據錯誤據、據互衝突,錯誤衝突據顯,稱“臟據”。按照規則“臟據”“洗掉”,據清洗。據清洗務濾符合求據,濾交業務主管部門,確認是否過濾掉還是由業務單位修正之後再進行抽取。不符合要求的數據主要是有不完整的數據、錯誤的數據、重複的數據三大類。數據清洗是與問卷審核不同,錄入后的數據清理一般是由計算機而不是人工完成。
致檢查( )根據量合取值範圍互系,檢查據否合乎求,超範圍、邏輯合互矛盾據。例,-級量測量量值,負,視超值域範圍。、、計算軟體夠根據義取值範圍,自動識別每個超出範圍的變數值。具有邏輯上不一致性的答案可能以多種形式出現:例如,許多調查對象說自己開車上班,又報告沒有汽車;或者調查對象報告自己是某品牌的重度購買者和使用者,但同時又在熟悉程度量表上給了很低的分值。發現不一致時,要列出問卷序號、記錄序號、變數名稱、錯誤類別等,便於進一步核對和糾正。
由於調查、編碼和錄入誤差,數據中可能存在一些無效值和缺失值,需要給予適當的處理。常用的處理方法有:估算,整例刪除,變數刪除和成對刪除。
估算(estimation)。最簡單的辦法就是用某個變數的樣本均值、中位數或眾數代替無效值和缺失值。這種辦法簡單,但沒有充分考慮數據中已有的信息,誤差可能較大。另一種辦法就是根據調查對象對其他問題的答案,通過變數之間的相關分析或邏輯推論進行估計。例如,某一產品的擁有情況可能與家庭收入有關,可以根據調查對象的家庭收入推算擁有這一產品的可能性。
整例刪除(casewise deletion)是剔除含有缺失值的樣本。由於很多問卷都可能存在缺失值,這種做法的結果可能導致有效樣本量大大減少,無法充分利用已經收集到的數據。因此,只適合關鍵變數缺失,或者含有無效值或缺失值的樣本比重很小的情況。
變數刪除(variable deletion)。如果某一變數的無效值和缺失值很多,而且該變數對於所研究的問題不是特別重要,則可以考慮將該變數刪除。這種做法減少了供分析用的變數數目,但沒有改變樣本量。
成對刪除(pairwise deletion)是用一個特殊碼(通常是9、99、999等)代表無效值和缺失值,同時保留數據集中的全部變數和樣本。但是,在具體計算時只採用有完整答案的樣本,因而不同的分析因涉及的變數不同,其有效樣本量也會有所不同。這是一種保守的處理方法,最大限度地保留了數據集中的可用信息。
採用不同的處理方法可能對分析結果產生影響,尤其是當缺失值的出現並非隨機且變數之間明顯相關時。因此,在調查中應當盡量避免出現無效值和缺失值,保證數據的完整性。
數據清洗原理:利用有關技術如數理統計、數據挖掘或預定義的清理規則將臟數據轉化為滿足數據質量要求的數據。
這一類數據主要是一些應該有的信息缺失,如供應商的名稱、分公司的名稱、客戶的區域信息缺失、業務系統中主表與明細表不能匹配等。對於這一類數據過濾出來,按缺失的內容分別寫入不同Excel文件向客戶提交,要求在規定的時間內補全。補全后才寫入數據倉庫。
這一類錯誤產生的原因是業務系統不夠健全,在接收輸入后沒有進行判斷直接寫入後台資料庫造成的,比如數值數據輸成全形數字字元、字元串數據後面有一個回車操作、日期格式不正確、日期越界等。這一類數據也要分類,對於類似於全形字元、數據前後有不可見字元的問題,只能通過寫SQL語句的方式找出來,然後要求客戶在業務系統修正之後抽取。日期格式不正確的或者是日期越界的這一類錯誤會導致ETL運行失敗,這一類錯誤需要去業務系統資料庫用SQL的方式挑出來,交給業務主管部門要求限期修正,修正之後再抽取。
對於這一類數據——特別是維表中會出現這種情況——將重複數據記錄的所有欄位導出來,讓客戶確認並整理。
數據清洗是一個反覆的過程,不可能在幾天內完成,只有不斷的發現問題,解決問題。對於是否過濾,是否修正一般要求客戶確認,對於過濾掉的數據,寫入Excel文件或者將過濾數據寫入數據表,在ETL開發的初期可以每天向業務單位發送過濾數據的郵件,促使他們儘快地修正錯誤,同時也可以做為將來驗證數據的依據。數據清洗需要注意的是不要將有用的數據過濾掉,對於每個過濾規則認真進行驗證,並要用戶確認。
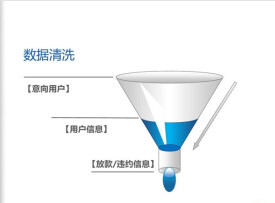
一般來說,數據清理是將資料庫精簡以除去重複記錄,並使剩餘部分轉換成標準可接收格式的過程。數據清理標準模型是將數據輸入到數據清理處理器,通過一系列步驟“清理”數據,然後以期望的格式輸出清理過的數據(如上圖所示)。數據清理從數據的準確性、完整性、一致性、惟一性、適時性、有效性幾個方面來處理數據的丟失值、越界值、不一致代碼、重複數據等問題。
數據清理一般針對具體應用,因而難以歸納統一的方法和步驟,但是根據數據不同可以給出相應的數據清理方法。
1.解決不完整數據(即值缺失)的方法
大多數情況下,缺失的值必須手工填入(即手工清理)。當然,某些缺失值可以從本數據源或其它數據源推導出來,這就可以用平均值、最大值、最小值或更為複雜的概率估計代替缺失的值,從而達到清理的目的。
2.錯誤值的檢測及解決方法
用統計分析的方法識別可能的錯誤值或異常值,如偏差分析、識別不遵守分佈或回歸方程的值,也可以用簡單規則庫(常識性規則、業務特定規則等)檢查數據值,或使用不同屬性間的約束、外部的數據來檢測和清理數據。
3.重複記錄的檢測及消除方法
資料庫中屬性值相同的記錄被認為是重複記錄,通過判斷記錄間的屬性值是否相等來檢測記錄是否相等,相等的記錄合併為一條記錄(即合併/清除)。合併/清除是消重的基本方法。
4.不一致性(數據源內部及數據源之間)的檢測及解決方法
從多數據源集成的數據可能有語義衝突,可定義完整性約束用於檢測不一致性,也可通過分析數據發現聯繫,從而使得數據保持一致。目前開發的數據清理工具大致可分為三類。
數據遷移工具允許指定簡單的轉換規則,如:將字元串gender替換成sex。sex公司的PrismWarehouse是一個流行的工具,就屬於這類。
數據清洗工具使用領域特有的知識(如,郵政地址)對數據作清洗。它們通常採用語法分析和模糊匹配技術完成對多數據源數據的清理。某些工具可以指明源的“相對清潔程度”。工具Integrity和Trillum屬於這一類。
數據審計工具可以通過掃描數據發現規律和聯繫。因此,這類工具可以看作是數據挖掘工具的變形。
基本信息
- 中文名
- 數據清洗
- 外文名
- Data cleaning
- 拼音
- shù jù qīng xǐ
- 術語類別
- 學術名詞
- 對象
- 數據
- 目的
- 發現並糾正數據文件