布隆過濾器
1970年由布隆提出的概念
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進位向量和一系列隨機映射函數。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都比一般的演演算法要好的多,缺點是有一定的誤識別率和刪除困難。
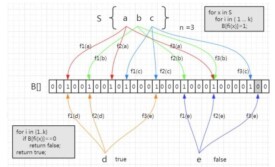
如果想要判斷一個元素是不是在一個集合里,一般想到的是將所有元素保存起來,然後通過比較確定。鏈表,樹等等數據結構都是這種思路. 但是隨著集合中元素的增加,我們需要的存儲空間越來越大,檢索速度也越來越慢。不過世界上還有一種叫作散列表(又叫哈希表,Hash table)的數據結構。它可以通過一個Hash函數將一個元素映射成一個位陣列(Bit array)中的一個點。這樣一來,我們只要看看這個點是不是1就可以知道集合中有沒有它了。這就是布隆過濾器的基本思想。
Hash面臨的問題就是衝突。假設Hash函數是良好的,如果我們的位陣列長度為m個點,那麼如果我們想將衝突率降低到例如 1%, 這個散列表就只能容納個元素。顯然這就不叫空間效率了(Space-efficient)了。解決方法也簡單,就是使用多個Hash,如果它們有一個說元素不在集合中,那肯定就不在。如果它們都說在,雖然也有一定可能性它們在說謊,不過直覺上判斷這種事情的概率是比較低的。
布隆過濾器
相比於其它的數據結構,布隆過濾器在空間和時間方面都有巨大的優勢。布隆過濾器存儲空間和插入/查詢時間都是常數。另外, Hash函數相互之間沒有關係,方便由硬體并行實現。布隆過濾器不需要存儲元素本身,在某些對保密要求非常嚴格的場合有優勢。
布隆過濾器可以表示全集,其它任何數據結構都不能。
但是布隆過濾器的缺點和優點一樣明顯。誤算率是其中之一。隨著存入的元素數量增加,誤算率隨之增加。常見的補救辦法是建立一個小的白名單,存儲那些可能被誤判的元素。但是如果元素數量太少,則使用散列表足矣。
另外,一般情況下不能從布隆過濾器中刪除元素。我們很容易想到把位列陣變成整數數組,每插入一個元素相應的計數器加1, 這樣刪除元素時將計數器減掉就可以了。然而要保證安全的刪除元素並非如此簡單。首先我們必須保證刪除的元素的確在布隆過濾器裡面. 這一點單憑這個過濾器是無法保證的。另外計數器迴繞也會造成問題。
在降低誤算率方面,有不少工作,使得出現了很多布隆過濾器的變種。
網頁URL的去重,垃圾郵件的判別,集合重複元素的判別,查詢加速(比如基於key-value的存儲系統)、資料庫防止查詢擊穿,使用BloomFilter來減少不存在的行或列的磁碟查找。
java代碼實現
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 | public class MyBloomFilter { private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61}; private static HashFunction[] functions = new HashFunction[seeds.length]; private static BitSet bitset = new BitSet(DEFAULT_SIZE); public static void add(String value) { if (value != null) { for (HashFunction f : functions) { //計算 hash 值並修改 bitmap 中相應位置為 true bitset.set(f.hash(value), true); } } } public static boolean contains(String value) { if (value == null) { return false; } boolean ret = true; for (HashFunction f : functions) { ret = bitset.get(f.hash(value)); //一個 hash 函數返回 false 則跳出循環 if (!ret) { break; } } return ret; } public static void main(String[] args) { for (int i = 0; i < seeds.length; i++) { functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]); } // 添加1億數據 for (int i = 0; i < 100000000; i++) { add(String.valueOf(i)); } String id = "123456789"; add(id); System.out.println(contains(id)); // true System.out.println("" + contains("234567890")); //false } } class HashFunction { private int size; private int seed; public HashFunction(int size, int seed) { this.size = size; this.seed = seed; } public int hash(String value) { int result = 0; int len = value.length(); for (int i = 0; i < len; i++) { result = seed * result + value.charAt(i); } int r = (size - 1) & result; return (size - 1) & result; } } |
基本信息
- 中文名
- 布隆過濾器
- 外文名
- Bloom Filter
- 提出時間
- 1970年
- 提出者
- 布隆