AVX指令集
Sandy Bridge和Larrabee架構下的新指令集
AVX指令集是Sandy Bridge和Larrabee架構下的新指令集。AVX是在之前的128位擴展到和256位的單指令多數據流。而Sandy Bridge的單指令多數據流演算單元擴展到256位的同時數據傳輸也獲得了提升,所以從理論上看CPU內核浮點運算性能提升到了2倍。
Intel AVX指令集,在單指令多數據流計算性能增強的同時也沿用了的MMX/SSE指令集。不過和MMX/SSE的不同點在於增強的AVX指令,從指令的格式上就發生了很大的變化。x86(IA-32/Intel 64)架構的基礎上增加了prefix(Prefix),所以實現了新的命令,也使更加複雜的指令得以實現,從而提升了x86 CPU的性能。
Intel的微架構進入了全速發展的時期,在2010年4月結束的IDF峰會上Intel公司就發布了2010年的RoadMap。2011年1月Intel發布了處理器微架構Sandy Bridge,其中全新增加的指令集也將帶來CPU性能的提升。
Intel公司將為Sandy Bridge帶來全新的指令擴展集Intel Advanced Vector Extensions (Intel AVX)。

全新指令集Intel AVX概要

2倍浮點運算性能
Intel全新的發展戰略也表明,從2010年開始軟體和新指令也將有更好的兼容,而單指令多數據流浮點運算(即實數運算)並非決定因素,所以CPU的性能就變得更加困難。而性能增強的同時,單指令多數據流浮點運算在已有編碼的基礎上也必須會有更大的提升空間,特別是scalar整數運算部分。目前單線程整數運算性能的提升也遇到了瓶頸,本次IDF展會上,確定了這一CPU開發方向的同時也表明了技術的進化趨勢。

2008年之後的Intel指令集
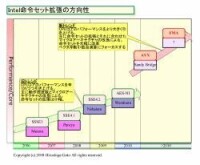
Intel指令集進化圖
AVX並不是x86 CPU的擴展指令集,可以實現更高的效率,同時和CPU硬體兼容性也更好,並且也有著足夠的擴展空間,這都和其全新的命令格式系統有關。更加流暢的架構就是AVX發展的方向,換言之,就是擺脫傳統x86的不足,在SSE指令的基礎上AVX也使SSE指令介面更加易用。
針對AVX的最新的命令編碼系統,Intel也給出了更加詳細的介紹,其中包括了大幅度擴充指令集的可能性。比如Sandy Bridge所帶來的融合了乘法的雙指令支持。從而可以更加容易地實現512位和1024位的擴展。而在2008年末到2009年推出的meniikoaCPU“Larrabee(LARAB)”處理器,就會採用AVX指令集。從地位上來看AVX也開始了Intel處理器指令集的新篇章。
AVX的256位單指令多數據流擴展支持是其最具革新的設計部分,同時也代表了指令編碼格式的變更。x86(IA-32/Intel 64)指令,在op code之前增加了一個位元組的prefix,從而實現了擴展的支持。增強的寄存器也使指令頭部分不斷增加prefix成為了可能。單指令多數據流指令也以SIMDprefix的身份出現,另外Intel 64也增加了8個寄存器從而實現了對於REXprefix的支持。
IA-32/Intel 64的另外一個優勢就是對於prefix的擴展,不過也存在一些不足,比如prefix指令格式變得更加複雜,而指令也更長等。因此IA-32/Intel 64的指令如果要實現decoding將增加難度,而decoding的同時也將帶來電力的消耗。實際上Core Microarchitecture(Core MA)所遇到的最大瓶頸,就是指令的puridekodo和fetch。而prefix的不斷增加也使指令的結尾產生了新的問題。
AVX的指令編碼系統的產生,同時也是SSE指令進化的必然。(IA-32/Intel 64)SIMD指令最初是3個位元組,不過對於追加的數據類型在這基礎之上,64-位 增加了8個1位元組的Prefix寄存器,並且在命令頭處增加了1位元組。Intel的Bob Valentine先生(CPU Architect, Mobility Group)對此進行了說明。
AVX對於變更編碼指令編碼格式方面,也有了解決辦法,其中增加了1個重疊位元組的prefix就成為低效率的解決方案,而VEX(Vector Extension)的prefix以及1-2個位元組的連續VEX的payload(Payload)系統,也成為相對完美的解決辦法。
VEX編碼的構想,就是壓縮Prefix中包含的信息,在1個位元組的payload中全部包括了prefix的內容。並且在今後導入的新的寄存器中,128位或更長的256位的數據,也將在payload中壓縮。

支持16路SIMD指令
實際上1位元組的payload也並不會全部載入,也有著2個版本的VEX,4位元組版本和5位元組版本。而對於大部分legacy編碼,即使是64位的指令,也可以支持4位元組指令寄存。而1位元組指令就變得更加短小了。而幾個全新的指令也使用了新的寄存器,所以增加了5位元組的版本。Valentine先生對VEX進行了相關的介紹。

Intel的Bob Valentine先生
其中5位元組版的payload
,也專門有著指令擴展的3比特空間,而3位也意味著1000條新指令的支持,全新的ficha和新的寄存器以及vector也都可以更加容易地增加。
除了VEX指令格式外還有著1,024位的SIMD的支持。同時多重prefix的支持和之前的beru比較,全部的指令在格式上都更小,之前的1位元組C5通過C4,也可以決定op code的長度。而從硬體上來看的話,指令的puridekodo實現也更加容易。
AVX的VEX的編碼系統,從某一側面上也反應了Intel處理器今後的進化趨勢,因為它解決了x86系列CPU在decoding上的不足。Core MA有著4條命令的執行通道,不過front end卻存在著不足,首先L1緩存fetch埠也有著16位元組的長度。而fetch的命令次數也被得到了限制。首先IA-32/Intel 64命令的puridekodo也有著先天的瓶頸,而操作數和地址長度的指令prefix“LCP(Length Changing Prefixes),使得puridekodo變得更慢,所以必須要改變長標註的演演算法。

fetch&puridekodo的最優化設計

AVX指令集
Core MA在puridekodo&decoding方面的不足,從根本上來看是IA-32/Intel 64指令集架構本身的問題。IA-32/Intel 64架構為了增強長命令而增設的緩存,使命令fetch的更長,並且更加複雜的命令格式也由此產生。RISC(Reduced Instruction Set Computer)的命令格式也決定了其長度,decoding雖然容易,但x86系CPU也就要以犧牲資源為代價,同時也帶來了電力的額外消耗。
實際上最新的Nehalem也有著類似Core MA的不足,從某種程度上來看也延續了其不足,如果明確了這一問題的話,那麼Nehalem就必須要改進,其中16bytesfetch和puridekodo等方面的改進就勢在必行了。而改進所需要的龐大晶體管增加,也會帶來功耗的增加。
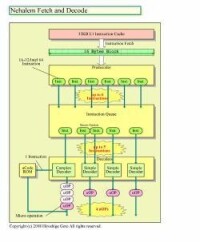
Nehalem結構圖
Nehalem的設計其實存在著疑問,不過從VEX格式來分析的話其意圖就非常明確了。Intel在完善了CPU的puridekodo&decoding硬體設計的同時,必須要改進指令格式本身。fetch的指令變短的同時,指令的標註卻更加複雜了,而解決的唯一辦法就是改進指令格式。
在充分考慮硬體方面設計后,intel做出了VEX格式開始的決策。IDF上Valentine先生也對VEX格式進行了詳細的說明。他是Core MA的front end的fetch開發以及decoding的高級架構師,同時也是IA-32/Intel 64指令編碼器的設計專家。
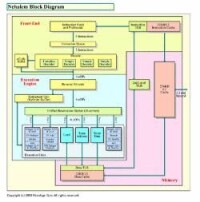
Core Architecture結構圖
AVX擴展指令包含了SSE指令,這也有助於AVX時代的過度。日前的SSEVEX格式也並不需要絕對的轉換過程。Intel公司的Benny Eitan先生也提到,出於整體的考慮,Intel公司對於AVX普及的進行並不會太過迅速,並且也不會立刻停止SSE及MMX時代。
Sandy Bridge也增強了解碼器的支持,和之前的IA-32/Intel 64prefix相比,decoding也有了全新的VEX格式的支持。其中VEX指令對於decoding的命令數的支持上更加強勁,同時VEX在執行效率上也更加出色。不過這些和Sandy Bridge真正到來的時候可能還存在差異。
目前AMD新推出FMA指令也 是 AVX 指令集中的一部分。
Intel 的FMA 指令是3 operands(操作數)的,被稱為 FMA3,而AMD的FMA是4 operands 的,被稱為 FMA4,AMD認為4 operands 更能提供效率。更加細化!
基本信息
- 中文名
- AVX指令集
- 屬於
- 進入了全速發展的時期
- 包括
- 2010年的RoadMap
- 發布
- 處理器微架構Sandy Bridge