信源編碼
減少、消除信源利余度的編碼
信源編碼(source coding)指針對各種信息源及不同目的所進行的編碼。傳統的信源編碼主要考慮信息的表示,例如早期的莫爾斯電碼、英文字元的ASCII編碼等,主要完成英文信息的二進位表示。現代數據通信系統中常見的信源編碼大部分與數據 壓縮有關,通過對原始數據的有損或無損壓縮編碼,可以極大地降低數據量,節省數據存儲和傳輸的開銷。例如: 常用的無損壓縮編碼方式有Huffman的編碼、算術編碼、L-Z編碼等;有損壓縮編碼方式有音樂的 MP3編碼、視頻流的H.264編碼等。此外,數據加密也可以是一類特殊的信源編碼技術。
既然信源編碼的基本目的是提高碼字序列中碼元的平均信息量,那麼,一切旨在減少剩餘度而對信源輸出符號序列所施行的變換或處理,都可以在這種意義下歸入信源編碼的範疇,例如過濾、預測、域變換和數據壓縮等。當然,這些都是廣義的信源編碼。
一般來說,減少信源輸出符號序列中的剩餘度、提高符號平均信息量的基本途徑有兩個:①使序列中的各個符號儘可能地互相獨立;②使序列中各個符號的出現概率儘可能地相等。前者稱為解除相關性,後者稱為概率均勻化。
信源編碼的一般問題可以表述如下:若某信源的輸出為長度等於M的符號序列集合
式中符號A為信源符號表,它包含著K個不同的符號,,這個信源至多可以輸出K個不同的符號序列。記。所謂對這個信源的輸出進行編碼,就是用一個新的符號表B的符號序列集合V來表示信源輸出的符號序列集合U。若V的各個序列的長度等於 N,即
式中新的符號表B共含L個符號,。它總共可以編出L個不同的碼字。類似地,記。為了使信源的每個輸出符號序列都能分配到一個獨特的碼字與之對應,至少應滿足關係
或者
假若編碼符號表B的符號數L與信源符號表A的符號數K相等,則編碼后的碼字序列的長度N必須大於或等於信源輸出符號序列的長度M;反之,若有,則必須有。只有滿足這些條件,才能保證無差錯地還原出原來的信源輸出符號序列(稱為碼字的唯一可譯性)。可是,在這些條件下,碼字序列的每個碼元所載荷的平均信息量不但不能高於,反而會低於信源輸出序列的每個符號所載荷的平均信息量。這與編碼的基本目標是直接相矛盾的。下面的幾個編碼定理,提供了解決這個矛盾的方法。它們既能改善信息載荷效率,又能保證碼字唯一可譯。
離散無記憶信源的定長編碼定理對於任意給定的,只要滿足條件
那麼,當M足夠大時,上述編碼幾乎沒有失真;反之,若這個條件不滿足,就不可能實現無失真的編碼。式中H(U)是信源輸出序列的符號熵。
通常,信源的符號熵,因此,上述條件還可以表示為
特別,若有,那麼只要,就可能有,從而提高信息載荷的效率。由上面這個條件可以看出,越遠,通過編碼所能獲得的效率改善就越顯著。實質上,定長編碼方法提高信息載荷能力的關鍵是利用了漸近等分性,通過選擇足夠大的M,把本來各個符號概率不等[因而的信源輸出符號序列變換為概率均勻的典型序列,而碼字的唯一可譯性則由碼字的定長性來解決。
離散無記憶信源的變長編碼定理變長編碼是指V的各個碼字的長度不相等。只要V中各個碼字的長度 滿足克拉夫特不等式
這 ‖V‖個碼字就能唯一地正確劃分和解碼。離散無記憶信源的變長編碼定理指出:若離散無記憶信源的輸出符號序列為
,式中 ,符號熵為H(U),對U進行唯一可譯的變長編碼,編碼字母表B的符號數為L,即,那麼必定存在一種編碼方法,使編出的碼字,具有平均長度嚻:
時,必有越遠,則嚻越小於M。
具體實現唯一可譯變長編碼的方法很多,但比較經典的方法還是仙農編碼法、費諾編碼法和霍夫曼編碼法。其他方法都是這些經典方法的變形和發展。所有這些經典編碼方法,都是通過以短碼來表示常出現的符號這個原則來實現概率的均勻化,從而得到高的信息載荷效率;同時,通過遵守克拉夫特不等式關係來實現碼字的唯一可譯。
霍夫曼編碼方法的具體過程是:首先把信源的各個輸出符號序列按概率遞降的順序排列起來,求其中概率最小的兩個序列的概率之和,並把這個概率之和看作是一個符號序列的概率,再與其他序列依概率遞降順序排列(參與求概率之和的這兩個序列不再出現在新的排列之中),然後,對參與概率求和的兩個符號序列分別賦予二進位數字0和1。繼續這樣的操作,直到剩下一個以1為概率的符號序列。最後,按照與編碼過程相反的順序讀出各個符號序列所對應的二進位數字組,就可分別得到各該符號序列的碼字。
例如,某個離散無記憶信源的輸出符號序列及其對應的概率分佈為
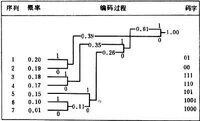
信源編碼
由表中可以看出,在碼字序列中碼元0和1的概率分別為,二者近乎相等,實現了概率的均勻化。同時,由於碼字序列長度滿足克拉夫特不等式
因而碼字是唯一可譯的,不會在長的碼字序列中出現划錯碼字的情況。
以上幾個編碼定理,在有記憶信源或連續信源的情形也有相應的類似結果。在實際工程應用中,往往並不追求無差錯的信源編碼和解碼,而是事先規定一個解碼差錯率的容許值,只要實際的解碼差錯率不超過這個容許值即認為滿意(見信息率-失真理論和多用戶信源編碼)。
參考書目
周炯槃:《信息理論基礎》,人民郵電出版社,北京, 1983。
有本卓,《現代情報理論》,電子通信學會,東京,1978。
信源編碼的作用之一是設法減少 碼元數目和降低 碼元速率,即通常所說的 數據壓縮;作用之二是將信源的 模擬信號轉化成 數字信號,以實現模擬信號的數字化傳輸。

表1 信源編碼實例表
其中,等長碼的平均碼長:=3,即三位碼。若採用赫夫曼編碼,平均碼長
,即不足兩位碼。這就是說,數據壓縮了以上。

基本信息
- 作用
- 減少碼元數目和降低碼元速率
- 外文名
- source coding