CAP
CAP原理
在CAP原理中,有三個要素分別是一致性、最終一致性和因果一致性。
目錄
致(CONSISTENCY)可用性(AVAILABILITY)分區容忍性(PARTITION TOLERANCE)CAP原理指的是,這三個要素最多只能同時實現兩點,不可能三者兼顧。因此在進行分散式架構設計時,必須做出取捨。而對於分散式數據系統,分區容忍性是基本要求,否則就失去了價值。因此設計分散式數據系統,就是在一致性和可用性之間取一個平衡。對於大多數WEB應用,其實並不需要強一致性,因此犧牲一致性而換取高可用性,是多數分散式資料庫產品的方向。
,犧牲致,完管據致,否則據混亂,系統布式價值。犧牲致,求關係型資料庫中的強一致性,而是只要系統能達到最終一致性即可,考慮到客戶體驗,這個最終一致的時間窗口,要儘可能的對用戶透明,也就是需要保障“用戶感知到的一致性”。通常是通過數據的多份非同步複製來實現系統的高可用和數據的最終一致性的,“用戶感知到的一致性”的時間窗口則取決於數據複製到一致狀態的時間。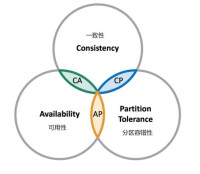
CAP
終致(EVENTUALLY CONSISTENT)
對於一致性,可以分為從客戶端和服務端兩個不同的視角。從客戶端來看,一致性主要指的是多併發訪問時更新過的數據如何獲取的問題。從服務端來看,則是更新如何複製分佈到整個系統,以保證數據最終一致。一致性是因為有併發讀寫才有的問題,因此在理解一致性的問題時,一定要注意結合考慮併發讀寫的場景。
從客戶端角度,多進程併發訪問時,更新過的數據在不同進程如何獲取的不同策略,決定了不同的一致性。對於關係型資料庫,要求更新過的數據能被後續的訪問都能看到,這是強一致性。如果能容忍後續的部分或者全部訪問不到,則是弱一致性。如果經過一段時間后要求能訪問到更新后的數據,則是最終一致性。
最終一致性根據更新數據后各進程訪問到數據的時間和方式的不同,又可以區分為:
因果一致性(CAUSAL CONSISTENCY)
如果進程A通知進程B它已更新了一個數據項,那麼進程B的後續訪問將返回更新后的值,且一次寫入將保證取代前一次寫入。與進程A無因果關係的進程C的訪問遵守一般的最終一致性規則。“讀己之所寫(READ-YOUR-WRITES)”一致性。當進程A自己更新一個數據項之後,它總是訪問到更新過的值,絕不會看到舊值。這是因果一致性模型的一個特例。會話(SESSION)一致性。這是上一個模型的實用版本,它把訪問存儲系統的進程放到會話的上下文中。只要會話還存在,系統就保證“讀己之所寫”一致性。如果由於某些失敗情形令會話終止,就要建立新的會話,而且系統的保證不會延續到新的會話。單調(MONOTONIC)讀一致性。如果進程已經看到過數據對象的某個值,那麼任何後續訪問都不會返回在那個值之前的值。單調寫一致性。系統保證來自同一個進程的寫操作順序執行。要是系統不能保證這種程度的一致性,就非常難以編程了。上述最終一致性的不同方式可以進行組合,例如單調讀一致性和讀己之所寫一致性就可以組合實現。並且從實踐的角度來看,這兩者的組合,讀取自己更新的數據,和一旦讀取到最新的版本不會再讀取舊版本,對於此架構上的程序開發來說,會少很多額外的煩惱。
從服務端角度,如何儘快將更新后的數據分佈到整個系統,降低達到最終一致性的時間窗口,是提高系統的可用度和用戶體驗非常重要的方面。對於分散式數據系統:
N — 數據複製的份數,W — 更新數據是需要保證寫完成的節點數,R — 讀取數據的時候需要讀取的節點數如果W+R>N,寫的節點和讀的節點重疊,則是強一致性。例如對於典型的一主一備同步複製的關係型資料庫,N=2,W=2,R=1,則不管讀的是主庫還是備庫的數據,都是一致的。
如果W+R<=N,則是弱一致性。例如對於一主一備非同步複製的關係型資料庫,N=2,W=1,R=1,則如果讀的是備庫,就可能無法讀取主庫已經更新過的數據,所以是弱一致性。
對於分散式系統,為了保證高可用性,一般設置N>=3。不同的N,W,R組合,是在可用性和一致性之間取一個平衡,以適應不同的應用場景。
如果N=W,R=1,任何一個寫節點失效,都會導致寫失敗,因此可用性會降低,但是由於數據分佈的N個節點是同步寫入的,因此可以保證強一致性。如果N=R,W=1,只需要一個節點寫入成功即可,寫性能和可用性都比較高。但是讀取其他節點的進程可能不能獲取更新后的數據,因此是弱一致性。這種情況下,如果W<(N+1)/2,並且寫入的節點不重疊的話,則會存在寫衝突。

基本信息
- 中文名
- CAP[CAP原理]