UTF-8
針對Unicode的可變長度字元編碼
UTF-8(8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字元編碼,也是一種前綴碼,又稱萬國碼。由Ken Thompson於1992年創建。它可以用來表示Unicode標準中的任何字元,且其編碼中的第一個位元組仍與ASCII兼容,這使得原來處理ASCII字元的軟體無須或只須做少部份修改,即可繼續使用。因此,它逐漸成為電子郵件、網頁及其他存儲或傳送文字的應用中,優先採用的編碼。

數據結構簡要
但是,由於它是針對英語設計的,當處理帶有音調標號(形如漢語的拼音)的亞洲文字時就會出現問題。因此,創建出了一些包括256個字元的由ASCII擴展的字符集。其中有一種通常被稱為IBM字符集,它把值為128-255之間的字元用於畫圖和畫線,以及一些特殊的歐洲字元。另一種8位字符集是ISO 8859-1Latin 1,也簡稱為ISOLatin-1。它把位於128-255之間的字元用於拉丁字母表中特殊語言字元的編碼,也因此而得名。歐洲語言不是地球上的唯一語言,因此亞洲和非洲語言並不能被8位字符集所支持。僅漢語字母表(或pictograms)就有80000以上個字元。但是把漢語、日語和越南語的一些相似的字元結合起來,在不同的語言里,使不同的字元代表不同的字,這樣只用2個位元組就可以編碼地球上幾乎所有地區的文字。因此,創建了UNICODE編碼。它通過增加一個高位元組對ISO Latin-1字符集進行擴展,當這些高位元組位為0時,低位元組就是ISO Latin-1字元。UNICODE支持歐洲、非洲、中東、亞洲(包括統一標準的東亞象形漢字和韓國表音文字)。但是,UNICODE並沒有提供對諸如Braille(盲文),Cherokee, Ethiopic(衣索比亞語), Khmer(高棉語), Mongolian(蒙古語), Hmong(苗語), Tai Lu, Tai Mau文字的支持。同時它也不支持如Ahom(阿霍姆語), Akkadian(阿卡德語), Aramaic(阿拉米語), Babylonian Cuneiform(古巴比倫楔形文字), Balti(巴爾蒂語), Brahmi(婆羅米文), Etruscan(伊特拉斯坎語), Hittite(赫梯語/西台語), Javanese(爪哇語),Numidian(努米底亞語), Old Persian Cuneiform(古波斯楔形文字),Syrian(敘利亞語)之類的古老文字。
Unicode只是一組字元設定或者說是從數字和字元之間的邏輯映射的概念編碼,但是它並沒有指定代碼點如何在計算機上存儲。UCS4、UTF-8、UTF-16(UTF后的數字代表編碼的最小單位,如UTF-8表示最小單位1位元組(=8 bits),所以它可以使用1、2、3位元組等進行編碼,UTF-16表示最小單位2位元組,所以它可以使用2、4位元組進行編碼)都是Unicode的編碼方案。其中UTF-8因可以兼容ASCII而被廣泛使用。
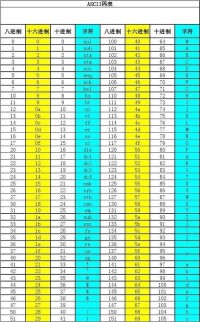
ASCII碼格式
如果UNICODE字元由2個位元組表示,則編碼成UTF-8很可能需要3個位元組。而如果UNICODE字元由4個位元組表示,則編碼成UTF-8可能需要6個位元組。用4個或6個位元組去編碼一個UNICODE字元可能太多了,但很少會遇到那樣的UNICODE字元。 UTF-8轉換表表示如下:
| Unicode/UCS-4 | bit數 | UTF-8 | byte數 | 備註 |
0000 ~ 007F | 0~7 | 0 XXX XXXX | 1 | |
0080 ~ 07FF | 8~11 | 110 X XXXX 10 XX XXXX | 2 | |
0800 ~ FFFF | 12~16 | 1110 XXXX 10 XX XXXX 10 XX XXXX | 3 | 基本定義範圍:0~FFFF |
1 0000 ~ 1F FFFF | 17~21 | 1111 0 XXX 10 XX XXXX 10 XX XXXX 10 XX XXXX | 4 | Unicode6.1定義範圍:0~10 FFFF |
20 0000 ~ 3FF FFFF | 22~26 | 1111 10 XX 10 XX XXXX 10 XX XXXX 10 XX XXXX 10 XX XXXX | 5 | 說明:此非unicode編碼範圍,屬於UCS-4 編碼 早期的規範UTF-8可以到達6位元組序列,可以覆蓋到31位元(通用字符集原來的極限)。儘管如此,2003年11月UTF-8 被 RFC 3629 重新規範,只能使用原來Unicode定義的區域, U+0000到U+10FFFF。根據規範,這些位元組值將無法出現在合法 UTF-8序列中 |
400 0000 ~ 7FFF FFFF | 27~31 | 1111 110 X 10 XX XXXX 10 XX XXXX 10 XX XXXX 10 XX XXXX 10 XX XXXX | 6 |
實際表示ASCII字元的UNICODE字元,將會編碼成1個位元組,並且UTF-8表示與ASCII字元表示是一樣的。所有其他的UNICODE字元轉化成UTF-8將需要至少2個位元組。每個位元組由一個換碼序列開始。第一個位元組由唯一的換碼序列,由n位連續的1加一位0組成, 首位元組連續的1的個數表示字元編碼所需的位元組數。
Unicode轉換為UTF-8時,可以將Unicode二進位從低位往高位取出二進位數字,每次取6位,如上述的二進位就可以分別取出為如下示例所示的格式,前面按格式填補,不足8位用0填補。
註:Unicode轉換為UTF-8需要的位元組數可以根據這個規則計算:如果Unicode小於0X80(Ascii字元),則轉換後為1個位元組。否則轉換后的位元組數為Unicode二進位位數加3再除以5。
示例
UNICODE uCA(1100 1010) 編碼成UTF-8將需要2個位元組:
uCA -> C3 8A
UNICODE uF03F (11110000 0011 1111) 編碼成UTF-8將需要3個位元組:
u F03F -> EF 80 BF
| Unicode 16進位 | Unicode 2進位 | bit數 | UTF-8 2進位 | UTF-8 16進位 |
| CA | 1100 1010 | 8 | 110 0 0011 10 00 1010 | C3 8A |
| F0 3F | 11110000 0011 1111 | 16 | 1110 1111 1 0 00 0000 10 11 1111 | EF 80 BF |
UTF-8編碼可以通過屏蔽位和移位操作快速讀寫。字元串比較時strcmp()和wcscmp()的返回結果相同,因此使排序變得更加容易。位元組FF和FE在UTF-8編碼中永遠不會出現,因此他們可以用來表明UTF-16或UTF-32文本(見BOM) UTF-8 是位元組順序無關的。它的位元組順序在所有系統中都是一樣的,因此它實際上並不需要BOM。
你無法從UNICODE字元數判斷出UTF-8文本的位元組數,因為UTF-8是一種變長編碼它需要用2個位元組編碼那些用擴展ASCII字符集只需1個位元組的字元 ISO Latin-1 是UNICODE的子集,但不是UTF-8的子集 8位字元的UTF-8編碼會被email網關過濾,因為internet信息最初設計為7位ASCII碼。因此產生了UTF-7編碼。 UTF-8 在它的表示中使用值100xxxxx的幾率超過50%,而現存的實現如ISO 2022, 4873, 6429,和8859系統,會把它錯認為是C1 控制碼。因此產生了UTF-7.5編碼。
UTF-8保存使用
標準UTF-8和修正的UTF-8有兩點不同:
修正的UTF-8中,null字元編碼成2個位元組(1100000010000000)而不是標準的1個位元組(00000000),這樣作可以保證編碼后的字元串中不會嵌入null字元。因此如果在類C語言中處理字元串,文本不會在第一個null字元時截斷(C字元串以'\0'結尾)。
在標準UTF-8編碼中,超出基本多語言範圍(BMP-Basic Multilingual Plane)的字元被編碼為4位元組格式,但是在修正的UTF-8編碼中,他們由代理編碼對(surrogatepairs)表示,然後這些代理編碼對在序列中分別重新編碼。結果標準UTF-8編碼中需要4個位元組的字元,在修正後的UTF-8編碼中將需要6個位元組。
“UTF-8”是標準寫法,php在Windows下邊英文不區分大小寫,所以也可以寫成“utf-8”。“UTF-8”也可以把中間的“-”省略,寫成“UTF8”。一般程序都能識別,但也有例外(如下文),為了嚴格一點,最好用標準的大寫“UTF-8”。
在資料庫中只能使用“utf8”(MySQL)在MySQL的命令模式中只能使用“utf8”,不能使用“utf-8”,也就是說在PHP程序中只能使用“set names utf8(不加小橫杠)”,如果你加了“-”此行命令將不會生效,但是在PHP中header時卻要加上“-”,因為IE不認識沒杠的“utf8”。
UCS字元U+0000到U+007F(ASCII)被編碼為位元組0×00到0x7F(ASCIⅡ兼容)。這意味著只包含7位ASCIl字元的文件在ASCIⅡ和UTF-8兩種編碼方式下是一樣的。
所有大於0x007F的UCS字元被編碼為一個有多個位元組的串,每個位元組都有標記位集。因此,ASCIl位元組(0x00-0x7F)不可能作為任何其他字元的一部分。表示非ASCIl字元的多位元組串的第一個位元組總是在0xC0到0XFD的範圍里,並指出這個字元包含多少個位元組。多位元組串的其餘位元組都在0x80到0xBF範圍里。這使得重新同步非常容易,並使編碼無國界,且很少受丟失位元組的影響。
UTF-8編碼字元理論上可以最多到4個位元組長,然而16位BMP字元最多只用到3位元組長,Bigendian UCS-4位元組串的排列順序是預定的,位元組0xFE和OxFF在UTF-8編碼中從未用到。
UTF-8使用1~4位元組為每個字元編碼:
·一個US-ASCIl字元只需1位元組編碼(Unicode範圍由U+0000~U+007F)。
·其他語言的字元(包括中日韓文字、東南亞文字、中東文字等)包含了大部分常用字,使用3位元組編碼。
·其他極少使用的語言字元使用4位元組編碼。

基本信息
- 外文名
- UTF-8, a transformation format of ISO 10646
- 定義
- 針對Unicode的可變長度字元編碼
- 針對
- Unicode
- 作者
- Rob Pike(羅布·派克)、Ken Thompson
- 創建時間
- 1992年09月
- 所屬領域
- 計算機科學技術