負荷預測
負荷預測
負荷預測是根據系統的運行特性、增容決策、自然條件與社會影響等諸多因數,在滿足一定精度要求的條件下,確定未來某特定時刻的負荷數據,其中負荷是指電力需求量(功率)或用電量;負荷預測是電力系統經濟調度中的一項重要內容,是能量管理系統(EMS)的一個重要模塊。
電力系統負荷一般可以分為城市民用負荷、商業負荷、農村負荷、工業負荷以及其他負荷等,不同類型的負荷具有不同的特點和規律。
城市民用負荷主要來自城市居民家用電器的用電負荷,它具有年年增長的趨勢,以及明顯的季節性波動特點,而且民用負荷的特點還與居民的日常生活和工作的規律緊密相關。
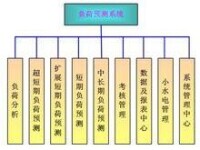
負荷預測系統構成
及工業負荷和民用負荷,但商業負荷中的照明類負荷佔用電力系統高峰時段。此外,商業部門由於商業行為在節假日會增加營業時間,從而成為節假日中影響電力負荷的重要因素之一。
工業負荷是指用於工業生產的用電,一般工業負荷的比重在用電構成中居於首位,它不僅取決於工業用戶的工作方式(包括設備利用情況、企業的工作班制等),而且與各行業的行業特點、季節因素都有緊密的聯繫,一般負荷是比較恆定的。
農村負荷則是指農村居民用電和農業生產用電。此類負荷與工業負荷相比,受氣候、季節等自然條件的影響很大,這是由農業生產的特點所決定的。農業用電負荷也受農作物種類、耕作習慣的影響,但就電網而言,由於農業用電負荷集中的時間與城市工業負荷高峰時間有差別,所以對提高電網負荷率有好處。
從以上分析可知電力負荷的特點是經常變化的,不但按小時變、按日變,而且按周變,按年變,同時負荷又是以天為單位不斷起伏的,具有較大的周期性,負荷變化是連續的過程,一般不會出現大的躍變,但電力負荷對季節、溫度、天氣等是敏感的,不同的季節,不同地區的氣候,以及溫度的變化都會對負荷造成明顯的影響。
電力負荷的特點決定了電力總負荷由以下四部分組成:基本正常負荷分量、天氣敏感負荷分量、特別事件負荷分量和隨機負荷分量。
負荷預測工作的關鍵在於收集大量的歷史數據,建立科學有效的預測模型,採用有效的演演算法,以歷史數據為基礎,進行大量試驗性研究,總結經驗,不斷修正模型和演演算法,以真正反映負荷變化規律。其基本過程如下。
1調查和選擇歷史負荷數據資料
多方面調查收集資料,包括電力企業內部資料和外部資料,從眾多的資料中挑選出有用的一小部分,即把資料濃縮到最小量。挑選資料時的標準要直接、可靠並且是最新的資料。如果資料的收集和選擇得不好,會直接影響負荷預測的質量。
2歷史資料的整理
一般來說,由於預測的質量不會超過所用資料的質量,所以要對所收集的與負荷有關的統計資料進行審核和必要的加工整理,來保證資料的質量,從而為保證預測質量打下基礎,即要注意資料的完整無缺,數字準確無誤,反映的都是正常狀態下的水平,資料中沒有異常的"分離項",還要注意資料的補缺,並對不可靠的資料加以核實調整。
3對負荷數據的預處理
在經過初步整理之後,還要對所用資料進行數據分析預處理,即對歷史資料中的異常值的平穩化以及缺失數據的補遺,針對異常數據,主要採用水平處理、垂直處理方法。
數據的水平處理即在進行分析數據時,將前後兩個時間的負荷數據作為基準,設定待處理數據的最大變動範圍,當待處理數據超過這個範圍,就視為不良數據,採用平均值的方法平穩其變化;數據的垂直處理即在負荷數據預處理時考慮其24h的小周期,即認為不同日期的同一時刻的負荷應該具有相似性,同時刻的負荷值應維持在一定的範圍內,對於超出範圍的不良數據修正,為待處理數據的最近幾天該時刻的負荷平均值。
4建立負荷預測模型
負荷預測模型是統計資料軌跡的概括,預測模型是多種多樣的,因此,對於具體資料要選擇恰當的預測模型,這是負荷預測過程中至關重要的一步。當由於模型選擇不當而造成預測誤差過大時,就需要改換模型,必要時,還可同時採用幾種數學模型進行運算,以便對比、選擇。
在選擇適當的預測技術后,建立負荷預測數學模型,進行預測工作。由於從已掌握的發展變化規律,並不能代表將來的變化規律,所以要對影響預測對象的新因素進行分析,對預測模型進行恰當的修正後確定預測值。
電力負荷預測分為經典預測方法和現代預測方法。
〖經典預測方法〗
趨勢外推法
就是根據負荷的變化趨勢對未來負荷情況作出預測。電力負荷雖然具有隨機性和不確定性,但在一定條件下,仍存在著明顯的變化趨勢,例如農業用電,在氣候條件變化較小的冬季,日用電量相對穩定,表現為較平穩的變化趨勢。這種變化趨勢可為線性或非線性,周期性或非周期性等等。
時間序列法
時間序列法是一種最為常見的短期負荷預測方法,它是針對整個觀測序列呈現出的某種隨機過程的特性,去建立和估計產生實際序列的隨機過程的模型,然後用這些模型去進行預測。它利用了電力負荷變動的慣性特徵和時間上的延續性,通過對歷史數據時間序列的分析處理,確定其基本特徵和變化規律,預測未來負荷。
時間序列預測方法可分為確定型和隨機性兩類,確定型時間序列作為模型殘差用於估計預測區間的大小。隨機型時間序列預測模型可以看作一個線性濾波器。根據線性濾波器的特性,時間序列可劃為自回歸(AR)、動平均(MA)、自回歸-動平均(ARMA)、累計式自回歸-動平均(ARIMA)、傳遞函數(TF)幾類模型,其負荷預測過程一般分為模型識別、模型參數估計、模型檢驗、負荷預測、精度檢驗預測值修正5個階段。
回歸分析法就是根據負荷過去的歷史資料,建立可以分析的數學模型,對未來的負荷進行預測。利用數理統計中的回歸分析方法,通過對變數的觀測數據進行分析,確定變數之間的相互關係,從而實現預測。
〖現代負荷預測方法〗
20世紀80年代後期,一些基於新興學科理論的現代預測方法逐漸得到了成功應用。這其中主要有灰色數學理論、專家系統方法、神經網路理論、模糊預測理論等。
灰色數學理論
灰色數學理論是把負荷序列看作一真實的系統輸出,它是眾多影響因子的綜合作用結果。這些眾多因子的未知性和不確定性,成為系統的灰色特性。灰色系統理論把負荷序列通過生成變換,使其變化為有規律的生成數列再建模,用於負荷預測。
專家系統方法
專家系統方法是對於資料庫里存放的過去幾年的負荷數據和天氣數據等進行細緻的分析,彙集有經驗的負荷預測人員的知識,提取有關規則。藉助專家系統,負荷預測人員能識別預測日所屬的類型,考慮天氣因素對負荷預測的影響,按照一定的推理進行負荷預測。
神經網路理論
神經網路理論是利用神經網路的學習功能,讓計算機學習包含在歷史負荷數據中的映射關係,再利用這種映射關係預測未來負荷。由於該方法具有很強的魯棒性、記憶能力、非線性映射能力以及強大的自學習能力,因此有很大的應用市場,但其缺點是學習收斂速度慢,可能收斂到局部最小點;並且知識表達困難,難以充分利用調度人員經驗中存在的模糊知識。
模糊負荷預測
模糊負荷預測是近幾年比較熱門的研究方向。
模糊控制是在所採用的控制方法上應用了模糊數學理論,使其進行確定性的工作,對一些無法構造數學模型的被控過程進行有效控制。模糊系統不管其是如何進行計算的,從輸入輸出的角度講它是一個非線性函數。模糊系統對於任意一個非線性連續函數,就是找出一類隸屬函數,一種推理規則,一個解模糊方法,使得設計出的模糊系統能夠任意逼近這個非線性函數。
〖模糊預測的一些基本方法〗
(1)表格查尋法:
表格法是一種相對簡單明了的演演算法。這個方法的基本思想是從已知輸入--輸出數據對中產生模糊規則,形成一個模糊規則庫,最終的模糊邏輯系統將從組合模糊規則庫中產生。
這是一種簡單易行的易於理解的演演算法,因為它是個順序生成過程,無需反覆學習,因此,這個方法同樣具有模糊系統優於神經網路系統的一大優點,即構造起來既簡單又快速。
(2)基於神經網路集成的高木-關野模糊預測演演算法:
它是利用神經網路來求得條件部輸入變數的聯合隸屬函數。結論部的函數f(X)也可以用神經網路來表示。神經網路均採用前向型的BP網路。
(3)改進的模糊神經網路模型的演演算法:
模糊神經網路即全局逼近器。模糊系統與神經網路似乎有著天然的聯繫,模糊神經網路在本質上是模糊系統的實現,就是將常規的神經網路(如前向反饋神經網路,HoPfield神經網路)賦予模糊輸入信號和模糊權。
對於複雜的系統建模,已經有了許多方法,並已取得良好的應用效果。但主要缺點是模型精度不高,訓練時間太長。此種方法的模型物理意義明顯,精度高,收斂快,屬於改進型演演算法。
(4)反向傳播學習演演算法:
模糊邏輯系統應用主要在於它能夠作為非線性系統的模型,包括含有人工操作員的非線性系統的模型。因此,從函數逼近意義上考慮,研究模糊邏輯系統的非線性映射能力顯得非常重要。函數逼近就是模糊邏輯系統可以在任意精度上,一致逼近任何定義在一個緻密集上的非線性函數,其優勢在於它有能夠系統而有效地利用語言信息的能力。萬能逼近定理表明一定存在這樣一個可以在任意精度逼近任意給定函數的高斯型模糊邏輯系統。反向傳播BP學習演演算法用來確定高斯型模糊邏輯系統的參數,經過辨識的模型能夠很好的逼近真實系統,進而達到提高預測精度的目的。