DHT
一種分散式存儲方法
DHT(Distributed Hash Table,分散式哈希表)類似Tracker的根據種子特徵碼返回種子信息的網路。DHT全稱叫分散式哈希表(Distributed Hash Table),是一種分散式存儲方法。在不需要伺服器的情況下,每個客戶端負責一個小範圍的路由,並負責存儲一小部分數據,從而實現整個DHT網路的定址和存儲。新版BitComet允許同時連接DHT網路和Tracker,也就是說在完全不連上Tracker伺服器的情況下,也可以很好的下載,因為它可以在DHT網路中尋找下載同一文件的其他用戶。
在BitComet中,無須作任何設置即可自動連接並使用DHT網路,完全不需要用戶干預。BitComet使用和TCP埠號相同的UDP埠進行DHT網路連接。如果要完全禁用DHT網路,可以在選項-高級-網路連接中禁用DHT網路。對於種子製作者,可以參考:種子文件製作
可以使用。當然,如果有可能打開路由器上所需埠的UDP轉發將更加有助於整個DHT網路的健壯性。
BitComet具體是怎樣連入DHT網路的
一般用戶是完全不需要理會這個具體過程的。這裡可以簡單的介紹一下:連入DHT網路的用戶叫做節點(node),節點之間互相有路由記錄,因此只要和任何一個已經在DHT網路中的節點連接上,客戶端就可以尋找到更多的節點,從而連入網路。
簡單地說:DHT技術就是可以使得網路中的任何一個機器都實現伺服器的部分功能,使得用戶的下載不再依靠於伺服器。用戶不需要干涉這個功能。對於普通用戶來說,不明白也沒有關係.
簡述
Kademlia(簡稱Kad)屬於一種典型的結構化P2P覆蓋網路(Structured P2P OverlayNetwork),以分散式的應用層全網方式來進行信息的存儲和檢索是其嘗試解決的主要問題。在Kademlia網路中,所有信息均以哈希表條目形式加以存儲,這些條目被分散地存儲在各個節點上,從而以全網方式構成一張巨大的分散式哈希表。我們可以形象地把這張哈希大表看成是一本字典:只要知道了信息索引的key,我們便可以通過Kademlia協議來查詢其所對應的value信息,而不管這個value信息究竟是存儲在哪一個節點之上。在eMule、BitTorrent等P2P文件交換系統中,Kademlia主要充當了文件信息檢索協議這一關鍵角色,但Kad網路的應用並不僅限於文件交換。下文的描述將主要圍繞eMule中Kad網路的設計與實現展開。
eMule的Kda存儲信息
只要是能夠表述成為字典條目形式的信息Kad網路均能存儲,一個Kad網路能夠同時存儲多張分散式哈希表。以eMule為例,在任一時刻,其Kad網路均存儲並維護著兩張分散式哈希表,一張我們可以將其命名為關鍵詞字典,而另一張則可以稱之為文件索引字典。
a. 關鍵詞字典:主要用於根據給出的關鍵詞查詢其所對應的文件名稱及相關文件信息,其中key的值等於所給出的關鍵詞字元串的160比特SHA1散列,而其對應的value則為一個列表,在這個列表當中,給出了所有的文件名稱當中擁有對應關鍵詞的文件信息,這些信息我們可以簡單地用一個3元組條目表示:(文件名,文件長度,文件的SHA1校驗值),舉個例子,假定存在著一個文件“warcraft_frozen_throne.iso”,當我們分別以“warcraft”、“frozen”、“throne”這三個關鍵詞來查詢Kad時,Kad將有可能分別返回三個不同的文件列表,這三個列表的共同之處則在於它們均包含著一個文件名為“warcraft_frozen_throne.iso”的信息條目,通過該條目,我們可以獲得對應iso文件的名稱、長度及其160比特的SHA1校驗值。
b. 文件索引字典:用於根據給出的文件信息來查詢文件的擁有者(即該文件的下載服務提供者),其中key的值等於所需下載文件的SHA1校驗值(這主要是因為,從統計學角度而言,160比特的SHA1文件校驗值可以唯一地確定一份特定數據內容的文件);而對應的value也是一個列表,它給出了當前所有擁有該文件的節點的網路信息,其中的列表條目我們也可以用一個3元組表示:(擁有者IP,下載偵聽埠,擁有者節點ID),根據這些信息,eMule便知道該到哪裡去下載具備同一SHA1校驗值的同一份文件了。
Kad搜索下載流程
基於我們對eMule的Kad網路中兩本字典的理解,利用Kad網路搜索並下載某一特定文件的基本過程便很明白了,仍以“warcraft_frozen_throne.iso”為例,首先我們可以通過warcraft、frozen、throne等任一關鍵詞查詢關鍵詞字典,得到該iso的SHA1校驗值,然後再通過該校驗值查詢Kad文件索引字典,從而獲得所有提供“warcraft_frozen_throne.iso”下載的網路節點,繼而以分段下載方式去這些節點下載整個iso文件。
在上述過程中,Kad網路實際上所起的作用就相當於兩本字典,但值得再次指出的是,Kad並不是以集中的索引伺服器(如華語P2P源動力、Razorback 2、DonkeyServer等,騾友們應該很熟悉吧)方式來實現這兩本字典的存儲和搜索的,因為這兩本字典的所有條目均分散式地存儲在參與Kad網路的各節點中,相關文件信息、下載位置信息的存儲和交換均無需集中索引伺服器的參與,這不僅提高了查詢效率,而且還提高了整個P2P文件交換系統的可靠性,同時具備相當的反拒絕服務攻擊能力;更有意思的是,它能幫助我們有效地抵制FBI的追捕,因為俗話說得好:法不治眾…看到這裡,相信大家都能理解“分散式信息檢索”所帶來的好處了吧。但是,這些條目究竟是怎樣存儲的呢?我們又該如何通過Kad網路來找到它們?不著急,慢慢來。
節點的ID和距離
Kad網路中的每一個節點均擁有一個專屬ID,該ID的具體形式與SHA1散列值類似,為一個長達160bit的整數,它是由節點自己隨機生成的,兩個節點擁有同一ID的可能性非常之小,因此可以認為這幾乎是不可能的。在Kad網路中,兩個節點之間距離並不是依靠物理距離、路由器跳數來衡量的,事實上,Kad網路將任意兩個節點之間的距離d定義為其二者ID值的逐比特二進位和數,即,假定兩個節點的ID分別為a與b,則有:d=a XORb。在Kad中,每一個節點都可以根據這一距離概念來判斷其他節點距離自己的“遠近”,當d值大時,節點間距離較遠,而當d值小時,則兩個節點相距很近。這裡的“遠近”和“距離”都只是一種邏輯上的度量描述而已;在Kad中,距離這一度量是無方向性的,也就是說a到b的距離恆等於b到a的距離,因為aXOR b==b XOR a
Kad條目存儲
從上文中我們可以發現節點ID與條目中key值的相似性:無論是關鍵詞字典的key,還是文件索引字典的key,都是160bit,而節點ID恰恰也是160bit。這顯然是有目的的。事實上,節點的ID值也就決定了哪些條目可以存儲在該節點之中,因為我們完全可以把某一個條目簡單地存放在節點ID值恰好等於條目中key值的那個節點處,我們可以將滿足(ID==key)這一條件的節點命名為目標節點N。這樣的話,一個查找條目的問題便被簡單地轉化成為了一個查找ID等於Key值的節點的問題。
由於在實際的Kad網路當中,並不能保證在任一時刻目標節點N均一定存在或者在線,因此Kad網路規定:任一條目,依據其key的具體取值,該條目將被複制並存放在節點ID距離key值最近(即當前距離目標節點N最近)的k個節點當中;之所以要將重複保存k份,這完全是考慮到整個Kad系統穩定性而引入的冗餘;這個k的取值也有講究,它是一個帶有啟發性質的估計值,挑選其取值的準則為:“在當前規模的Kad網路中任意選擇至少k個節點,令它們在任意時刻同時不在線的幾率幾乎為0”;k的典型取值為20,即,為保證在任何時刻我們均能找到至少一份某條目的拷貝,我們必須事先在Kad網路中將該條目複製至少20份。
由上述可知,對於某一條目,在Kad網路中ID越靠近key的節點區域,該條目保存的份數就越多,存儲得也越集中;事實上,為了實現較短的查詢響應延遲,在條目查詢的過程中,任一條目可被cache到任意節點之上;同時為了防止過度cache、保證信息足夠新鮮,必須考慮條目在節點上存儲的時效性:越接近目標結點N,該條目保存的時間將越長,反之,其超時時間就越短;保存在目標節點之上的條目最多能夠被保留24小時,如果在此期間該條目被其發布源重新發布的話,其保存時間還可以進一步延長。
Kad節點維護
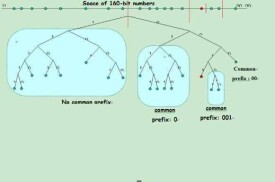
在Kad網路中,每一個節點均維護了160個list,其中的每個list均被稱之為一個k-桶(k-bucket),如下圖所示。在第i個list中,記錄了當前節點已知的與自身距離為2^i~2^(i+1)的一些其他對端節點的網路信息(NodeID,IP地址,UDP埠),每一個list(k-桶)中最多存放k個對端節點信息,注意,此處的k與上文所提到的複製係數k含義是一致的;每一個list中的對端節點信息均按訪問時間排序,最早訪問的在list頭部,而最新訪問的則放在list的尾部。
k-桶中節點信息的更新基本遵循Least-recently SeenEviction原則:當list容量未滿(k-桶中節點個數未滿k個),且最新訪問的對端節點信息不在當前list中時,其信息將直接添入list隊尾,如果其信息已經在當前list中,則其將被移動至隊尾;在k-桶容量已滿的情況下,添加新節點的情況有點特殊,它將首先檢查最早訪問的隊首節點是否仍有響應,如果有,則隊首節點被移至隊尾,新訪問節點信息被拋棄,如果沒有,這才拋棄隊首節點,將最新訪問的節點信息插入隊尾。可以看出,儘可能重用已有節點信息、並且按時間排序是k-桶節點更新方式的主要特點。從啟發性的角度而言,這種方式具有一定的依據:在線時間長一點的節點更值得我們信任,因為它已經在線了若干小時,因此,它在下一個小時以內保持在線的可能性將比我們最新訪問的節點更大,或者更直觀點,我這裡再給出一個更加人性化的解釋:MP3文件交換本身是一種觸犯版權法律的行為,某一個節點反正已經犯了若干個小時的法了,因此,它將比其他新加入的節點更不在乎再多犯一個小時的罪……-_-b
由上可見,設計採用這種多k-bucket數據結構的初衷主要有二:a. 維護最新到的節點信息更新;b.實現快速的節點信息篩選操作,也就是說,只要知道某個需要查找的特定目標節點N的ID,我們便可以從當前節點的k-buckets結構中迅速地查出距離N最近的若干已知節點。
Kad尋找節點
已知某節點ID,查找獲得當前Kad網路中與之距離最短的k個節點所對應的網路信息(NodeID,IP地址,UDP埠)的過程,即為Kad網路中的一次節點查詢過程(NodeLookup)。注意,Kad之所以沒有把節點查詢過程嚴格地定義成為僅僅只查詢單個目標節點的過程,這主要是因為Kad網路並沒有對節點的上線時間作出任何前提假設,因此在多數情況下我們並不能肯定需要查找的目標節點一定在線或存在。
整個節點查詢過程非常直接,其方式類似於DNS的迭代查詢:
a. 由查詢發起者從自己的k-桶中篩選出若干距離目標ID最近的節點,並向這些節點同時發送非同步查詢請求;
b .被查詢節點收到請求之後,將從自己的k-桶中找出自己所知道的距離查詢目標ID最近的若干個節點,並返回給發起者;
c. 發起者在收到這些返回信息之後,再次從自己所有已知的距離目標較近的節點中挑選出若干沒有請求過的,並重複步驟1;
d. 上述步驟不斷重複,直至無法獲得比查詢者當前已知的k個節點更接近目標的活動節點為止。
e. 在查詢過程中,沒有及時響應的節點將立即被排除;查詢者必須保證最終獲得的k個最節點都是活動的。
簡單總結一下上述過程,實際上它跟我們日常生活中去找某一個人打聽某件事是非常相似的,比方說你是個AgentSmith,想找小李(key)問問他的手機號碼(value),但你事先並不認識他,你首先肯定會去找你所認識的和小李在同一個公司工作的人,比方說小趙,然後小趙又會告訴你去找與和小李在同一部門的小劉,然後小劉又會進一步告訴你去找和小李在同一個項目組的小張,最後,你找到了小張,喲,正好小李出差去了(節點下線了),但小張恰好知道小李的號碼(cache),這樣你總算找到了所需的信息。在節點查找的過程中,“節點距離的遠近”實際上與上面例子中“人際關係的密切程度”所代表的含義是一樣的。
最後說說上述查詢過程的局限性:Kad網路並不適合應用於模糊搜索,如通配符支持、部分查找等場合,但對於文件共享場合來說,基於關鍵詞的精確查找功能已經基本足夠了(值得注意的是,實際上我們只要對上述查找過程稍加改進,並可以令其支持基於關鍵詞匹配的布爾條件查詢,但仍不夠優化)。這個問題反映到eMule的應用層面來,它直接說明了文件共享時其命名的重要性所在,即,文件名中的關鍵詞定義得越明顯,則該文件越容易被找到,從而越有利於其在P2P網路中的傳播;而另一方面,在eMule中,每一個共享文件均可以擁有自己的相關註釋,而Comment的重要性還沒有被大家認識到:實際上,這個文件註釋中的關鍵詞也可以直接被利用來替代文件名關鍵詞,從而指導和方便用戶搜索,尤其是當文件名本身並沒有體現出關鍵詞的時候。
Kad存儲和搜索條目
從本質上而言,存儲、搜索某特定條目的問題實際上就是節點查找的問題。當需要在Kad網路中存儲一個條目時,可以首先通過節點查找演演算法找到距離key最近的k個節點,然後再通知它們保存條目即可。而搜索條目的過程則與節點查詢過程也是基本類似,由搜索發起方以迭代方式不斷查詢距離key較近的節點,一旦查詢路徑中的任一節點返回了所需查找的value,整個搜索的過程就結束。為提高效率,當搜索成功之後,發起方可以選擇將搜索到的條目存儲到查詢路徑的多個節點中,作為方便後繼查詢的cache;條目cache的超時時間與節點-key之間的距離呈指數反比關係。
新節點加入Kad
當一個新節點首次試圖加入Kad網路時,它必須做三件事,其一,不管通過何種途徑,獲知一個已經加入Kad網路的節點信息(我們可以稱之為節點I),並將其加入自己的k-buckets;其二,向該節點發起一次針對自己ID的節點查詢請求,從而通過節點I獲取一系列與自己距離鄰近的其他節點的信息;最後,刷新所有的k-bucket,保證自己所獲得的節點信息全部都是新鮮的。
雙氫睾酮,血液循環中的一種雄激素,其他的包括脫氫表雄酮硫酸鹽(DHEAS)、脫氫表雄酮(DHEA)、雄烯二酮 (Δ4A)
男性型脫髮的病因基本明了,公認為發病因素是遺傳因素和雄激素二氫睾酮(DHT)綜合所致,抑制DHT的藥物非那雄胺可以很明顯地保持頭髮不被掉落。科學證明:當頭皮中含有大量DHT時,便會出現頭髮毛囊萎縮,頭髮的生長期縮短和頭髮變稀疏。
本病有明顯家族發病傾向,可以形成遺傳。根據科學分析,脫髮遺傳不僅要看父母,還要看雙方的家族,如叔、伯、舅舅等。如禿髮發生在女方,癥狀比男性輕,所以有時病發生在母親一方癥狀可能不太明顯,而在舅舅會更明顯些。但禿髮女性比禿髮男性攜帶更多的易感基因。
此外患者頭皮中雙氫睾酮的水平比正常人要高,而雙氫睾酮是睾酮在5α還原酶(DHT)的催化下形成的。5α還原酶中的第二型主要分佈於毛囊,在這種酶作用下,大量睾酮轉變為雙氫睾酮,後者作用於毛囊,導致毛囊的萎縮。
對於男性型脫髮,過去還沒有確實有效療法,一種二型5α還原酶抑製劑保法止用於該病的治療取得了顯著的療效,這種藥物可抑制雙氫睾酮的形成,從而使得毛囊能夠維持正常的生長周期,減少由終毛向毳毛的變化,從而就抑制了脫髮,據國內外研究,患者每天服用1mg保法止可顯著抑制脫髮,並可使頭髮密度加深,能夠達到很理想的美容效果。但是應當早期用藥和堅持用藥,否則會影響療效。
基本信息
- 中文名
- 分散式哈希表
- 外文名
- Distributed Hash Table
- 用途
- 內網用
- 類別
- 存儲方法
- 功能
- 伺服器功能
- 網路
- P2P覆蓋網路