散列值
區塊鏈領域的演演算法技術
散列函數(或散列演演算法,又稱哈希函數,英語:Hash Function)是一種從任何一種數據中創建小的數字“指紋”的方法。散列函數把消息或數據壓縮成摘要,使得數據量變小,將數據的格式固定下來。該函數將數據打亂混合,重新創建一個叫做散列值(hash values,hash codes,hash sums,或hashes)的指紋。散列值通常用一個短的隨機字母和數字組成的字元串來代表。好的散列函數在輸入域中很少出現散列衝突。在散列表和數據處理中,不抑制衝突來區別數據,會使得資料庫記錄更難找到。
所有散列函數都有如下一個基本特性:如果兩個散列值是不相同的(根據同一函數),那麼這兩個散列值的原始輸入也是不相同的。這個特性是散列函數具有確定性的結果,具有這種性質的散列函數稱為單向散列函數。但另一方面,散列函數的輸入和輸出不是唯一對應關係的,如果兩個散列值相同,兩個輸入值很可能是相同的,但也可能不同,這種情況稱為“散列碰撞(collision)”,這通常是兩個不同長度的輸入值,刻意計算出相同的輸出值。輸入一些數據計算出散列值,然後部分改變輸入值,一個具有強混淆特性的散列函數會產生一個完全不同的散列值。
典型的散列函數都有非常大的定義域,比如SHA-2最高接受(2-1)/8長度的位元組字元串。同時散列函數一定有著有限的值域,比如固定長度的比特串。在某些情況下,散列函數可以設計成具有相同大小的定義域和值域間的單射。散列函數必須具有不可逆性。
由於散列函數的應用的多樣性,它們經常是專為某一應用而設計的。例如,加密散列函數假設存在一個要找到具有相同散列值的原始輸入的敵人。一個設計優秀的加密散列函數是一個“單向”操作:對於給定的散列值,沒有實用的方法可以計算出一個原始輸入,也就是說很難偽造。為加密散列為目的設計的函數,如SHA-2,被廣泛的用作檢驗散列函數。這樣軟體下載的時候,就會對照驗證代碼之後才下載正確的文件部分。此代碼有可能因為環境因素的變化,如機器配置或者IP地址的改變而有變動。以保證源文件的安全性。
錯誤監測和修複函數主要用於辨別數據被隨機的過程所擾亂的事例。當散列函數被用於校驗和的時候,可以用相對較短(但不能短於某個安全參數, 通常不能短於160位)的散列值來驗證任意長度的數據是否被更改過。
主條目:加密散列函數
一個典型的加密單向函數是“非對稱”的,並且由一個高效的散列函數構成;一個典型的加密暗門函數是“對稱”的,並且由一個高效的隨機函數構成。
消息或數據的接受者確認消息是否被篡改的性質叫數據的真實性,也稱為完整性。發信人通過將原消息和散列值一起發送,可以保證真實性。
主條目:散列表
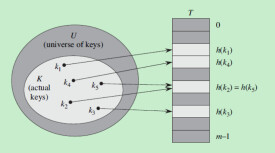
散列表是散列函數的一個主要應用,使用散列表能夠快速的按照關鍵字查找數據記錄。(注意:關鍵字不是像在加密中所使用的那樣是秘密的,但它們都是用來“解鎖”或者訪問數據的。)例如,在英語字典中的關鍵字是英文單詞,和它們相關的記錄包含這些單詞的定義。在這種情況下,散列函數必須把按照字母順序排列的字元串映射到為散列表的內部數組所創建的索引上。
散列表散列函數的幾乎不可能/不切實際的理想是把每個關鍵字映射到唯一的索引上(參考完美散列),因為這樣能夠保證直接訪問表中的每一個數據。
一個好的散列函數(包括大多數加密散列函數)具有均勻的真正隨機輸出,因而平均只需要一兩次探測(依賴於裝填因子)就能找到目標。同樣重要的是,隨機散列函數不太會出現非常高的衝突率。但是,少量的可以估計的衝突在實際狀況下是不可避免的(參考生日悖論或鴿洞原理)。
在很多情況下,heuristic散列函數所產生的衝突比隨機散列函數少的多。Heuristic函數利用了相似關鍵字的相似性。例如,可以設計一個heuristic函數使得像FILE0000.CHK,FILE0001.CHK,FILE0002.CHK,等等這樣的文件名映射到表的連續指針上,也就是說這樣的序列不會發生衝突。相比之下,對於一組好的關鍵字性能出色的隨機散列函數,對於一組壞的關鍵字經常性能很差,這種壞的關鍵字會自然產生而不僅僅在攻擊中才出現。性能不佳的散列函數表意味著查找操作會退化為費時的線性搜索。
主條目:錯誤校正與檢測
使用一個散列函數可以很直觀的檢測出數據在傳輸時發生的錯誤。在數據的發送方,對將要發送的數據應用散列函數,並將計算的結果同原始數據一同發送。在數據的接收方,同樣的散列函數被再一次應用到接收到的數據上,如果兩次散列函數計算出來的結果不一致,那麼就說明數據在傳輸的過程中某些地方有錯誤了。這就叫做冗餘校驗。
校正錯誤時,至少會對可能出現的擾動大致假定一個分佈模式。對於一個信息串的微擾可以被分為兩類,大的(不可能的)錯誤和小的(可能的)錯誤。我們對於第二類錯誤重新定義如下,假如給定H(x)和x+s,那麼只要s足夠小,我們就能有效的計算出x。那樣的散列函數被稱作錯誤校正編碼。這些錯誤校正編碼有兩個重要的分類:循環冗餘校驗和里德-所羅門碼。
對於像從一個已知列表中匹配一個MP3文件這樣的應用,一種可能的方案是使用傳統的散列函數——例如MD5,但是這種方案會對時間平移、CD讀取錯誤、不同的音頻壓縮演演算法或者音量調整的實現機制等情況非常敏感。使用一些類似於MD5的方法有利於迅速找到那些嚴格相同(從音頻文件的二進位數據來看)的音頻文件,但是要找到全部相同(從音頻文件的內容來看)的音頻文件就需要使用其他更高級的演演算法了。
那些並不緊隨IT工業潮流的人往往能反其道而行之,對於那些微小差異足夠健壯的散列函數確實存在。現存的絕大多數散列演演算法都是不夠健壯的,但是有少數散列演演算法能夠達到辨別從嘈雜房間里的揚聲器里播放出來的音樂的健壯性。有一個實際的例子是Shazam服務。用戶可以用手機打開其app,並將話筒靠近用於播放音樂的揚聲器。該項服務會分析正在播放的音樂,並將它於存儲在資料庫中的已知的散列值進行比較。用戶就能夠收到被識別的音樂的曲名。
Rabin-Karp字元串搜索演演算法是一個相對快速的字元串搜索演演算法,它所需要的平均搜索時間是O(n).這個演演算法是創建在使用散列來比較字元串的基礎上的。
基本信息
- 中文名
- 散列值
- 外文名
- hash function
- 領域
- 區塊鏈