遞歸網路
遞歸網路
遞歸網路是一種表示學習,它可以將詞、句、段、篇按照他們的語義映射到同一個向量空間中,也就是把可組合(樹/圖結構)的信息表示為一個個有意義的向量。
遞歸神經網路將所有的詞、句都映射到一個2維向量空間中。句子(the country of my birth)和句子(the place where I was born)的意思是非常接近的,所以表示它們的兩個向量在向量空間中的距離很近。另外兩個詞(Germany)和(France)因為表示的都是地點,它們的向量與上面兩句話的向量的距離,就比另外兩個表示時間的詞(Monday)和(Tuesday)的向量的距離近得多。這樣,通過向量的距離,就得到了一種語義的表示。
上圖還顯示了自然語言可組合的性質:詞可以組成句、句可以組成段落、段落可以組成篇章,而更高層的語義取決於底層的語義以及它們的組合方式。遞歸神經網路是一種表示學習,它可以將詞、句、段、篇按照他們的語義映射到同一個向量空間中,也就是把可組合(樹/圖結構)的信息表示為一個個有意義的向量。
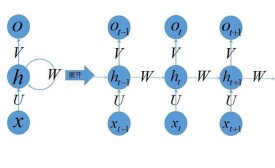
2、代表時刻的隱藏狀態。
3、代表時刻的輸出。
4、輸入層到隱藏層直接的權重由表示,它將我們的原始輸入進行抽象作為隱藏層的輸入。
5、隱藏層到隱藏層的權重,它是網路的記憶控制者,負責調度記憶。
6、隱藏層到輸出層的權重,從隱藏層學習到的表示將通過它再一次抽象,並作為最終輸出。
循環神經網路(Recurrent Neural Networks,RNNs)已經在眾多自然語言處理(Natural Language Processing, NLP)中取得了巨大成功以及廣泛應用。但是,目前網上與RNNs有關的學習資料很少,因此該系列便是介紹RNNs的原理以及如何實現。主要分成以下幾個部分對RNNs進行介紹:
1. RNNs的基本介紹以及一些常見的RNNs(本文內容);
2. 詳細介紹RNNs中一些經常使用的訓練演演算法,如Back Propagation Through Time(BPTT)、Real-time Recurrent Learning(RTRL)、Extended Kalman Filter(EKF)等學習演演算法,以及梯度消失問題(vanishing gradient problem)
3. 詳細介紹Long Short-Term Memory(LSTM,長短時記憶網路);
4. 詳細介紹Clockwork RNNs(CW-RNNs,時鐘頻率驅動循環神經網路);
5. 基於Python和Theano對RNNs進行實現,包括一些常見的RNNs模型。