大小端模式
數據位元組的保存模式
大小端模式是指數據的位元組保存在內存的高低地址中呈現的形式。
Big-Endian: 低地址存放高位,如下:
高地址
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
低地址
Little-Endian: 低地址存放低位,如下:
高地址
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
低地址
| 內存地址 | 小端模式存放內容 | 大端模式存放內容 |
| 0x4000 | 0x78 | 0x12 |
| 0x4001 | 0x56 | 0x34 |
| 0x4002 | 0x34 | 0x56 |
| 0x4003 | 0x12 | 0x78 |
大端模式
所謂的大端模式(Big-endian),是指數據的高位元組,保存在內存的低地址中,而數據的低位元組,保存在內存的高地址中,這樣的存儲模式有點兒類似於把數據當作字元串順序處理:地址由小向大增加,而數據從高位往低位放;
例子:
0000430: e684 6c4e 0100 1800 53ef 0100 0100 0000
0000440: b484 6c4e 004e ed00 0000 0000 0100 0000
在大端模式下,前32位應該這樣讀: e6 84 6c 4e ( 假設int佔4個位元組)
記憶方法: 地址的增長順序與值的增長順序相反
小端模式
所謂的小端模式(Little-endian),是指數據的高位元組保存在內存的高地址中,而數據的低位元組保存在內存的低地址中,這種存儲模式將地址的高低和數據位權有效地結合起來,高地址部分權值高,低地址部分權值低,和我們的邏輯方法一致。
例子:
0000430: e684 6c4e 0100 1800 53ef 0100 0100 0000
0000440: b484 6c4e 004e ed00 0000 0000 0100 0000
在小端模式下,前32位應該這樣讀: 4e 6c 84 e6( 假設int佔4個位元組)
記憶方法: 地址的增長順序與值的增長順序相同
大小端模式
為什麼會有大小端模式之分呢?這是因為在計算機系統中,我們是以位元組為單位的,每個地址單元都對應著一個位元組,一個位元組為 8bit。但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具體的編譯器),另外,對於位數大於 8位的處理器,例如16位或者32位的處理器,由於寄存器寬度大於一個位元組,那麼必然存在著一個如何將多個位元組安排的問題。因此就導致了大端存儲模式和小端存儲模式。例如一個16bit的short型x,在內存中的地址為0x0010,x的值為0x1122,那麼0x11為高位元組,0x22為低位元組。對於 大端模式,就將0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,剛好相反。我們常用的X86結構是小端模式,而KEIL C51則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以隨時在程序中(在ARM Cortex 系列使用REV、REV16、REVSH指令)進行大小端的切換。
圖解
對於0x11223344 儲存如下
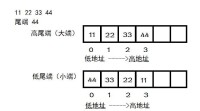
大小端模式
在喬納森·斯威夫特的著名諷刺小說《格列夫遊記》中,小人國內部分裂成Big-endian和Little-endian兩派,區別在於一派要求從雞蛋的大頭把雞蛋打破,另一派要求從雞蛋的小頭把雞蛋打破。斯威夫特藉以諷刺英國的政黨之爭,在計算機工業中指數據儲存順序的分歧。
編輯器模式
下面這段代碼可以用來測試一下你的編譯器是大端模式還是小端模式:
1 2 3 4 5 | short int x; char x0,x1; x=0x1122; x0=((char*)&x)[0]; //低地址單元 x1=((char*)&x)[1]; //高地址單元 |
若x0=0x11,則是大端; 若x0=0x22,則是小端......
從上面的程序還可以看出,數據定址時,用的是低位位元組的地址。
簡單大小端轉換的宏
1 2 3 4 | #definesw16(x)\ ((short)(\ (((short)(x)&(short)0x00ffU)<<8)|\ (((short)(x)&(short)0xff00U)>>8))) |
1 2 | #define ENDIANNESS ((char)endian_test.l) |
(如果ENDIANNESS=’l’表示系統為little endian,為’b’表示big endian )。
通過下列的程序可以確認在某個硬體平台上的某個操作系統是大端還是小端:
VB6:
注意這個CopyMemory的聲明與一般的不一樣, 一般的都是(pDst As Any, pSrc As Any, ByVal ByteLen As Long) 為了能夠逐位元組訪問u,所以前面兩個參數改成了按值傳遞,配合VarPtr函數獲取變數地址 Private Declare Sub CopyMemory Lib "kernel32" Alias _ "RtlMoveMemory" (ByVal pDst As Long, ByVal pSrc As Long, ByVal ByteLen As Long) Private Sub Form_Load() VB的Integer佔用2個位元組!Long才是4個位元組 32位應用程序的指針是4個位元組 Dim uptr As Long Dim aptr As Long Dim bptr As Long Dim cptr As Long Dim dptr As Long Dim u As Long ' 儲存u從低地址到高地址的4個位元組 Dim a As Byte Dim b As Byte Dim c As Byte Dim d As Byte u = 367328153 ' 十六進位數:15 E4 FB 99 uptr = VarPtr(u) ' VarPtr函數是內置函數,但是msdn不說,作用是獲取變數的地址 aptr = VarPtr(a) bptr = VarPtr(b) cptr = VarPtr(c) dptr = VarPtr(d) CopyMemory aptr, uptr + 0, 1 ' 將u逐位元組按順序寫入a,b,c,d CopyMemory bptr, uptr + 1, 1 CopyMemory cptr, uptr + 2, 1 CopyMemory dptr, uptr + 3, 1 ' Windows系統,英特爾處理器:最後輸出的是99 FB E4 15 MsgBox Hex(a) & " " & Hex(b) & " " & Hex(c) & " " & Hex(d) End Sub |
在英特爾處理器,Windows10操作系統上,對話框顯示的結果是99 FB E4 15,與直接求出來的16進位值15 E4 FB 99正好相反,所以是小端的。
C++語言(VS2013下,控制台項目):
using namespace std; typedef unsigned char byte; // 轉換char(視為整數類型)為16進位字元串 void ChtoHex(byte Val, char* dest) { // 輾轉相除法,倒序看得到結果 byte tmp = Val % 16; if (tmp >= 0 && tmp <= 9) { dest[1] = '0' + tmp; } else if (tmp >= 10 && tmp <= 15) { dest[1] = 'A' + tmp - 10; } tmp = (Val/16) % 16; if (tmp >= 0 && tmp <= 9) { dest[0] = '0' + tmp; } else if (tmp >= 10 && tmp <= 15) { dest[0] = 'A' + tmp - 10; } // 設置'\0' dest[2] = '\0'; } // 主函數 int main() { int u = 367328153; // 原始數據,8位16進位為15 E4 FB 99 byte a, b, c, d; // u從低地址到高地址的四個位元組 // a~d對應的16進位字元串,預留3個字元 char Sa[3], Sb[3], Sc[3], Sd[3]; byte* k = (byte*)&u; a = k[0]; b = k[1]; c = k[2]; d = k[3]; // 轉成16進位字元串 ChtoHex(a, Sa); ChtoHex(b, Sb); ChtoHex(c, Sc); ChtoHex(d, Sd); cout << Sa << " " << Sb << " " << Sc << " " << Sd << endl; system("pause"); return 0; } |
在英特爾處理器,Windows10操作系統上,控制台顯示的結果是99 FB E4 15,與直接求出來的16進位值15 E4 FB 99正好相反,所以也證明是小端的。
C語言(VC++6.0,控制台工程):
#include typedef unsigned char byte; // 轉換char(視為整數類型)為16進位字元串 void ChtoHex(byte Val, char* dest) { // 輾轉相除法,倒序看得到結果 byte tmp = Val % 16; if (tmp >= 0 && tmp <= 9) { dest[1] = '0' + tmp; } else if (tmp >= 10 && tmp <= 15) { dest[1] = 'A' + tmp - 10; } tmp = (Val/16) % 16; if (tmp >= 0 && tmp <= 9) { dest[0] = '0' + tmp; } else if (tmp >= 10 && tmp <= 15) { dest[0] = 'A' + tmp - 10; } // 設置\0 dest[2] = '\0'; } // 主函數 void main() { int u = 367328153; // 原始數據,8位16進位為15 E4 FB 99 byte a, b, c, d; // u從低地址到高地址的四個位元組 // a~d對應的16進位字元串,預留3個字元 char Sa[3], Sb[3], Sc[3], Sd[3]; byte* k = (byte*)&u; a = k[0]; b = k[1]; c = k[2]; d = k[3]; // 轉成16進位字元串 ChtoHex(a, Sa); ChtoHex(b, Sb); ChtoHex(c, Sc); ChtoHex(d, Sd); printf("%s %s %s %s\n", Sa, Sb, Sc, Sd); scanf_s("%d", &a); } |
在英特爾處理器,Windows10操作系統上,結果跟上面是一樣的,輸出的16進位數是反序的,證明是小端系統。
C#(VS2013下,控制台項目):
using System; namespace ConsoleApplication1 { class Program { static void Main(string[] args) { int u = 367328153; // 原始數據,8位16進位為15 E4 FB 99 byte[] bytes; // u從低地址到高地址的四個位元組 // 獲取 bytes = System.BitConverter.GetBytes(u); Console.WriteLine( bytes[0].ToString("X") + " " + bytes[1].ToString("X") + " " + bytes[2].ToString("X") + " " + bytes[3].ToString("X") ); Console.ReadLine(); } } } |
在英特爾處理器,Windows10操作系統上,結果跟上面還還是一樣的,輸出的16進位數是反序的,證明是小端系統。
MDK(Keil5,STM32F407)C語言:
#include "stm32f4xx.h" int main(void) { int u = 367328153; // 原始數據15 E4 FB 99 int* k = &u; return 0; } |
編譯連接然後下載到開發板上,然後啟動調試,通過監視窗口可以看到u的地址,然後在內存窗口可以看到位元組序是反序的,所以說明STM32F407是小端的。據某些資料說ARM內核是可以設置大小端的,但是STM32是外設自動進入了小端,似乎是無法調整的。
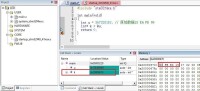
大小端模式
最後來一個大端的例子。手頭上沒有51的開發板,所以用的是軟體模擬。
#include int main() { int longbit = sizeof(long); long u = 367328153; // 原始數據15 E4 FB 99 long* k = &u; return 0; } |
注意看了,C52是8位的處理器,long才是4個位元組的,看監視窗口longbit的值就知道了(紫色框)。然後再看內存窗口,就會發現u的存儲是跟原始數據給的順序是一樣的,所以C51和C52是大端的!!
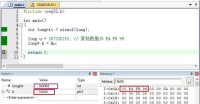
大小端模式

基本信息
- 中文名
- 大小端模式
- 外文名
- Big-endian/Little-endian
- 拼音
- dà xiǎo duān mó shì