網路丟包率
數據包丟失與所傳總數的比值
所謂網路丟包率是數據包丟失部分與所傳數據包總數的比值。正常傳輸時網路丟包率應該控制在一定範圍內。
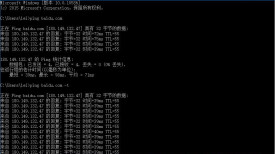
在cmd 中鍵入ping [網址],顯示最後一行(x% loss)就是對目標地址ping包的丟包率。
網路丟包是我們在使用ping(檢測某個系統能否正常運行)對目站進行詢問時,數據包由於各種原因在通道中丟失的現象。ping使用了ICMP回送請求與回送回答報文。ICMP回送請求報文是主機或路由器向一個特定的目的主機發出的詢問,收到此報文的機器必須給源主機發送ICMP回送回答報文。這種詢問報文用來測試目的站是否可到達以及了解其狀態。需要指出的是,ping是直接使用網路層ICMP的一個例子,它沒有通過運輸層的UDP或TCP。
網路丟包的原因主要有物理線路故障、設備故障、病毒攻擊、路由信息錯誤等,下面我們結合具體情況進行說明。
如果廣域網線路是通過路由器實現的,可以登錄到路由器,通過擴展ping向對端路由器廣域網介面發送大量的數據包進行測試。
如果線路是通過三層交換機實現,可在線路兩端分別接一台計算機,並將IP地址分別設為本端三層路由交換機的廣域網介面地址,使用“ping 對端計算機地址 -t”命令進行測試。
如果上述測試沒有發生丟包現象,則說明線路運營商提供的線路是好的,引起故障的原因在於用戶自身,需要進一步查找。
如果上述測試發生丟包現象,則說明故障是由線路供應商提供的線路引起的,需要與線路供應商聯繫儘快解決問題。
由物理線路引起的丟包現象還有很多,如光纖連接問題,跳線沒有對準設備介面,雙絞線及RJ-45接頭有問題等。另外,通信線路受到隨機雜訊或者突發雜訊造成的數據報錯誤,射頻信號的干擾和信號的衰減等都可能造成數據包的丟失。我們可以藉助網路測試儀來檢查線路的質量。
筆者近日在工作中發現一交換機埠的光纖模塊故障造成的丟包現象,該交換機在通信一段時間后死機,即不能通信,重啟后恢復正常。在經過一段時間觀察后發現,某光纖模塊存在問題,取一塊新的模塊替換,一切正常。究其原因,交換機會對所有接收到的數據包進行CRC錯誤檢測和長度校驗,將檢查出有錯誤的包丟棄,正確的包轉發出去。但這個過程中有些有錯誤的包在CRC錯誤檢測和長度校驗中都均未檢測出錯誤,這樣的包在轉發過程中不會被發送出去,也不會被丟棄,它們將會堆積在動態緩存中,永遠無法發送出去,等到緩存中堆積滿了,就會造成交換機死機的現象。最終結果是,數據包無法到達目的主機。
網路擁塞造成丟包率上升的原因很多,主要是路由器資源被大量佔用造成的。
如果發現網速慢,並且丟包率呈現上升的情況,這時應該show process cpu和show process mem,一般情況下發現IP input process佔用過多的資源。接下來可以檢查fast switching在大流量外出埠是否被禁用,如果是,則需要重新使用。
再看一下Fast switching on the same interface是否被禁用,如一個介面配有多個網段並且這些網段間流量很大時,路由器工作在process-switches方式,這種情況下要在介面上執行命令“enable ip route-cache same-interface”。
接下來,用show interfaces和show interfaces switching命令識別大量包進出的埠。一旦確認進入埠后,打開IP accounting on the outgoing interface看其特徵,如果是攻擊,源地址會不斷變化但是目的地址不變,可以用命令“access list”暫時解決此類問題(最好在接近攻擊源的設備上配置),最終解決辦法是停止攻擊源。
應用中遇到的造成網路擁塞的情況還有很多,如大量的UDP流量,可以用解決spoof attack的步驟解決此問題。大量的組播流、廣播包穿越路由器,路由器配置了IP NAT並且有很多DNS包穿越路由器等。上述情況造成網路擁塞后,通信雙方採取流量控制,丟棄不能傳輸的包。
網路路徑錯誤也會導致數據包不能到達目的主機,如主機的默認路由配置錯誤,主機發出的訪問其他網路的數據包會被網關丟棄。但此類丟包屬於正常情況下的丟包,是意料之中的,不會對網路造成影響。
基本信息
- 中文名
- 網路丟包率
- 拼音
- wǎng luò diū bāo lǜ
- 定義
- 指數據包丟失部分與所傳數據包總數的比值
- 類型
- 計算機網路術語
- 內容
- 最後一行(x% loss)
- 原因
- 物理線路故障、設備故障
- 學科
- 計算機學