多級存儲體系
多級存儲體系
多級存儲體系是指將多級存儲器結合起來的一種方式。在一個計算機系統中,對存儲器的容量、速度和價格這三個基本性能指標都有一定的要求。存儲容量應確保各種應用的需要;存儲器速度應盡量與CPU的速度相匹配並支持I/O操作;存儲器的價格應比較合理。然而,這三者經常是互相矛盾的。例如存儲器的速度越快,則每位的價格就越高;存儲器的容量越大,則存儲器的速度就越慢。按照現有的技術水平,僅僅採用一種技術組成單一的存儲器是不可能同時滿足這些要求的。只有採用由多級存儲器組成的存儲體系,把幾種存儲技術結合起來,才能較好地解決存儲器大容量、高速度和低成本這三者之間的矛盾。
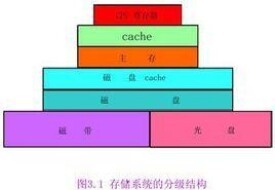
存儲器的多級結構如概述圖所示。圖中最內層是CPU中的通用寄存器,很多運算可直接在CPU的通用寄存器中進行,減少了CPU與主存的數據交換,很好地解決了速度匹配的問題,但通用寄存器的數量是有限的一般在幾個到幾百個之間,如Pentium CPU中有8個32位的通用寄存器。
高速緩衝存儲器(Cache)設置在CPU和主存之間,可以放在CPU 內部或外部。其作用也是解決主存與CPU的速度匹配問題。Cache一般是由高速SRAM組成,其速度要比主存高1到2個數量級。由主存與Cache構成的“主存-Cache存儲層次,從CPU來看,有接近於Cache的速度與主存的容量,並有接近於主存的每位價格。通常,Cache還分為一級Cache和二級Cache。
但是,以上兩層僅解決了速度匹配問題,存儲器的容量仍受到內存容量的制約。因此,在多級存在儲結構中又增設了輔助存儲器(由磁碟構成)和大容量存儲器(由磁帶構成)。隨著操作系統和硬體技術的完善,主存之間的信息傳送均可由操作系統中的存儲管理部件和相應的硬體自動完成,從而構成了主存一輔存的價格,從而彌補了主存容量不足的問題。
多級存儲結構構成的存儲體系是一個整體。從CPU看來,這個整體的速度接近於Cache和寄存器的操作速度、容量是輔存的容量,每位價格接近於輔存的位價格。從而較好地解決了存儲器中速度、容量、價格三者之間的矛盾,滿足了計算機系統的應用需要。
隨著半導體工藝水平的發展和計算機技術的進步,存儲器多級結構的構成可能會有所調整,但由多級半導體存儲器晶元集成度的提高,主存容量可能會達到幾百兆位元組或更高,但由於系統軟體和應用軟體的發展,主存的容量總是滿足不了應用的需求,只要這一現狀仍然存在,由主存――輔存為主體的多級存儲體系也就會長期存在下去。
iSCSI協議是網路存儲領域最活躍的研究方向之一,它建立在存儲領域和網路領域應用最廣泛的兩個協議,(SCSI TCP/IP)SCSI 基礎之上。它不僅解決了原有的匯流排長度有限,存儲設備擴展能力不足的問題,還可以利用現有的乙太網路實現基於協議的存儲網路,大大減少了企業在TCP/IP存儲方面的開支。
各種電子系統複雜度越來越高,對系統的可用性(availability)的要求也越來越高。從概率學的角度來說,系統的可用性是一個時間函數,定義為:系統正常工作並A(t)在時刻能執行它的功能的概率。其實,簡單來說,一個高t可用性系統,就是一個用戶能(High Availability System HA)隨時使用的系統,系統中斷服務的時間被期望為無窮小,使系統能一天24小時、一年365天不間斷地工作。
(1)二元元件模型以及可用性指標
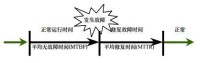
圖1 服務維護周期
(2)建立馬爾可夫過程模型
從簡單的元件模型分析得到了提高系統可用性的關鍵指標,要進行量化的最適用方案研究就必須要藉助隨機過程理論來進行數學分析了。為了建立更加成熟的模型,採用時域連續的馬爾可夫鏈作為工具,其狀態根據概率因素(Markov)而變化。對於存儲系統的主要部件而言,其正常工作時間和故障后的修理時間的分佈均為指數分佈,據此定義系統的狀態,並用馬爾可夫鏈來描述系統。
系統的狀態定義如下:系統初始狀態為0。一個節點出現故障,則狀態數加1;而一個故障節點恢復正常,則狀態數減1。也就是說,某時刻系統的狀態為n,則表示該時刻系統有n個節點處於故障狀態。
(1)多級協同存儲系統結構分析
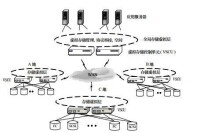
圖2 多級存儲系統結構示意圖
其中的關鍵部件是虛擬存儲控制單元,它是界於各類應用服務和存儲資源之間的軟硬體結合體,VSCU一方面為各種應用提供統一的連接和通信手段,另一方面,還提供存儲池管理功能。VSCU包含iSCSI Target模塊、 iSCSI Initiator模塊、虛擬邏輯單元管理、虛擬邏輯卷管理模塊、Web管理模塊等子模塊,並且連接客戶端、Web管理客戶端、SCSI設備端,幾乎包含了多級協同存儲系統中最重要的模塊和提供了幾乎全部的功能,其重要性毋庸置疑。在考慮本系統的高可用性時,把它看作系統中最重要的單點失效點。
(2)高可用性方案
根據以上的理論建模分析,針對多級協同存儲系統結構的分析結論,我們提出以下方案:
1) 要提高整個系統的高可用性,最重要的是提高VSCU的可用性。至於其他元件,例如SCSI設備的可用性可以通過RAID等技術解決,不在本課題考慮範圍內。
2)本課題的主要問題是解決本地子系統的高可用性,針對帶內(也就是本地區域網內)的VSCU構建HA子系統,遠程的VSCU之間的備份與恢復屬於容災課題。
3)根據數學分析,選用雙機高可用方案已經足以滿足需要。為了提高整個系統的高效率,高可用系統結構選用“集中式”結構,即任意時間只有一個結點作為主伺服器提供服務。一旦主伺服器出現故障,備份伺服器就接替其工作。

圖3 兩個連續的雙字
在多級存儲系統中,A、B這兩個雙字還有可能會出現不同的Cache行,還可能處在不同的存儲層次中(如A在一級Cache,B在外存等),這些複雜性加劇了跨邊界訪問問題的解決難度,因此必須採用高效合理的辦法加以解決。
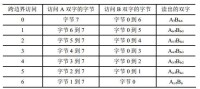
表1 連續雙字可能出現的7種跨邊界的讀雙字操作
圖4 程序員眼中的存儲空間
圖5 處理器眼中的存儲空間
(1)早期依靠編譯技術的解決方案
在大多數不支持跨邊界訪問的計算機裡面,需要編譯器在用戶進行數據定義和空間分配時提供額外的支持。這個過程稱為填充(pad),對程序員是透明的,造成的結果是一些程序員定義的結構實際佔用的空間比程序員自己想象的要大,填充的實質是用犧牲空間的辦法來提高程序的執行效率。一方面由於這種靠編譯的解決方案存在著對空間的浪費,另一方面隨著向量處理能力的需要和SIMD的流行,早期僅僅依靠編譯技術來避免跨邊界訪問的辦法已經行不通,因此在一些處理器中初步提供跨邊界訪問指令,如MIPS提供了跨邊界讀和跨邊界寫指令,但是這兩類指令都是偽指令,是通過一組基本指令來完成的,如ulw(跨邊界訪問一個字)指令是由兩個載入操作、一個移位操作、一個按位或操作組成的,這種情況下一個跨邊界訪問的周期很長,類似的還有DEC公司的Alpha處理器。
(2)依賴額外的數據對齊寄存器的解決方案
ADI公司的TTIGERSHARK處理器利用多個跨邊界操作之間的數據相關性,以及一個額外的硬體資源稱為數據對齊寄存器來解決跨邊界訪問的問題。TIGERSHARK的設計者認為這種跨邊界訪問操作雖然是不按邊界對齊的,但是往往是對許多個連續地址的訪問,這樣硬體就可以通過一個寄存器保存上次訪問的地址的內容,以便在下次訪問中能夠用到這次寄存的數據,儘可能減少對存儲體的訪問,降低訪問開銷。通過數據對齊寄存器,理想情況下能夠達到在連續地址的跨邊界訪問中每個周期提供一個數據的目標。
(3)依賴於單體單位元組存儲體的解決方案
基本信息
- 中文名
- 多級存儲體系
- 外文名
- Multi-level storage system
- 屬性
- 多級存儲
- 結構
- 構成的存儲體系是一個整體
- 性質
- 體系