真核基因組
真核基因組
真核基因組:由真核基因編碼的以及感染真核生物的DNA和RNA病毒編碼的基因組。真核生物基因組DNA與蛋白質結合形成染色體,儲存於細胞核內,除配子細胞外,體細胞內的基因的基因組是雙份的(即雙倍體,diploid),即有兩份同源的基因組
真核生物的基因組一般比較龐大,例如人的單倍體基因組由3×106 bp鹼基組成,按1000個鹼基編碼一種蛋白質計,理論上可有300萬個基因。但實際上,人細胞中所含基因總數大概會超過10萬個。這就說明在人細胞基因組中有許多DNA序列並不轉錄成mRNA用於指導蛋白質的合成。DNA的復性動力學研究發現這些非編碼區往往都是一些大量的重複序列,這些重複序列或集中成簇,或分散在基因之間。在基因內部也有許多能轉錄但不翻譯的間隔序列(內含子)。因此,在人細胞的整個基因組當中只有很少一部分(約佔2-3%)的DNA序列用以編碼蛋白質。
1.徠真核生物基因組DNA與蛋白質結合形成染色體,儲存於細胞核內,除配子細胞外,體細胞內的基因的基因組是雙份的(即雙倍體,diploid),即有兩份同源的基因組。
2.真核細胞基因轉錄產物為單順反子。一個結構基因經過轉錄和翻譯生成一個mRNA分子和一條多肽鏈。
3.存在重複序列,重複次數可達百萬次以上。
4.基因組中不編碼的區域多於編碼區域。
5.大部分基因含有內含子,因此,基因是不連續的。
6.基因組遠遠大於原核生物的基因組,具有許多複製起點,而每個複製子的長度較小。
高度重複序列在基因組中重複頻率高,可達10^3以上,因此復性速度很快。在基因組中所佔比例隨種屬而異,約佔10-60%,在人基因組中約佔20%。高度重複順序又按其結構特點分為三種。
這種重複順序復性速度極快,即使在極稀的DNA濃度下,也能很快復性,因此又稱零時復性部分,約佔人基因組的5%。反向重複序列由兩個相同順序的互補拷貝在同一DNA鏈上反向排列而成。變性后再復性時,同一條鏈內的互補的拷貝可以形成鏈內鹼基配對,形成髮夾式或“+”字形結構。倒位重複(即兩個互補拷貝)間可有一到幾個核苷酸的間隔,也可以沒有間隔。沒有間隔的又稱迴文(palimdr-ome),這種結構約佔所有倒位重複的三分之一。若以兩個互補拷貝組成的倒位重複為一個單位,則倒位重複的單位約長300bp或略少。兩個單位之間有一平均1.6kb的片段相隔,兩對倒位重複單位之間的平均距離約12kb,亦即它們多數散布非群集於基因組中。
衛星DNA(satelliteDNA)是另一類高度重複序列,這類重複順序的重複單位一般由2-10bp組成,成串排列。由於這類序列的鹼基組成不同於其他部份,可用等密度梯度離心法將其與主體DNA分開,因而稱為衛星DNA或隨體DNA。在人細胞組中衛星DNA約佔5-6%。按照它們的浮力密度不同,人的衛星DNA可分為Ⅰ、Ⅱ、Ⅲ、Ⅳ四種。果蠅的衛星DNA順序已經搞清楚,可分為三類,這三類衛星DNA都是由7bp組成的高度重複順序:衛星Ⅰ為5'ACAACT3',衛星Ⅱ為5'ACAAATT3'。而蟹的衛星DNA為只有AT兩個鹼基的重複順序組成。
這種重複順序為靈長類所獨有。用限制性內切酶HindⅢ消化非洲綠猴DNA,可以得到重複單位為172bp的高度重複順序,這種順序大部份由交替變化的嘌呤和嘧啶組成。有人把這類稱為α衛星DNA。而人的α衛星DNA更為複雜,含有多順序家族。
a.參與複製水平的調節反向序列常存在於DNA複製起點區的附近。另外,許多反向重複序列是一些蛋白質(包括酶)和DNA的結合位點。
b.參與基因表達的調控DNA的重複順序可以轉錄到核內不均一RNA分子中,而有些反向重複順序可以形成髮夾結構,這對穩定RNA分子,免遭分解有重要作用.
c.參與轉位作用幾乎所有轉位因子的末端都包括反向重複順序,長度由幾個bp到1400bp。由於這種順序可以形成迴文結構,因此在轉位作用中即能連接非同源的基因,又可以被參與轉位的特異酶所識別。
d.與進化有關不同種屬的高度重複順序的核苷酸序列不同,具有種屬特異性,但相近種屬又有相似性。如人的α衛星DNA長度僅差1個鹼基(前者為171bp,後者為172bp),而且鹼基序列有65%是相同的,這表明它們來自共同的祖先。在進化中某些特殊區段保守的,而其他區域的鹼基序列則累積著變化。
e.同一種屬中不同個體的高度重複順序的重複次數不一樣,這可以作為每一個體的特徵,即DNA指紋
f.α衛星DNA成簇的分佈在染色體著絲粒附近,可能與染色體減數分裂時染色體配對有關,即同源染色體之間的聯會可能依賴於具有染色體專一性的特定衛星DNA順序。
中度重複序列大致指在真核基因組中重複數十至數萬(<105)次的重複順序。其復性速度快於單拷貝順序,但慢於高度重複順序。少數在基因組中成串排列在一個區域,大多數與單拷貝基因間隔排列。依據重複順序的長度,中度重複順序可分為兩種類型。
(short interspersed repeated segments, SINES)這類重複順序的平均長度約為300bp(〈500bp),它們與平均長度約為1000bp的單拷貝順序間隔排列。拷貝數可達10萬左右。如Alu家族,Hinf家族等屬於這種類型的中度重複序列。
(Long interspersed repeated segments, LINES)這類重複順序的長度大於1000bp,平均長度為3500-5000bp,它們與平均長度為13000bp(個別長幾萬bp)的單拷貝順序間隔排列。也有的實驗顯示人基因組中所有LINES之間的平均距離為2.2kb,拷貝數一般在1萬左右,如KpnⅠ家族等。中度重複順序在基因組中所佔比例在不同種屬之間差異很大,一般約佔10-40%,在人約為12%。這些順序大多不編碼蛋白質。這些非編碼的中度重複順序的功能可能類似於高度重複順序。在結構基因之間,基因簇中,以及內含子內都可以見到這些短的和長的中度重複順序。按本文的分類原則有些中度重複順序則是編碼蛋白質或rRNA的結構基因,如HLA基因,rRNA基因,tRNA基因,組蛋白基因,免疫球蛋白基因等。中度重複順序一般具有種特異性;在適當的情況下,可以應用它們作為探針區分不同種哺乳動物細胞的DNA。
Alu家族是哺乳動物包括人基因組中含量最豐富的一種中度重複順序家族,在單倍體人基因組中重複達30萬-50萬次,約佔人基因組的3-6%。Alu家族每個成員的長度約300bp,由於每個單位長度中有一個限制性內切酶Alu的切點(AG↓CT)從而將其切成長130和170bp的兩段,因而定名為Alu序列(或Alu家族)。Alu序列分散在整個人體或其他哺乳動物基因組中,在間隔DNA,內含子中都發現有Alu序列,平均每5kbDNA就有一個Alu順序。已建立的基因組中無例外地含有Alu順序。Alu順序具有種的特異性,人的Alu順序製備的探針只能用於檢測人的基因組中的Alu序列。由於在大多數的含有人的DNA的克隆中都含有Alu順序,因此,可以這樣認為,用人的Alu序列製備的探針與要篩選的克隆雜交,陽性者即為含有人DNA克隆,陰性者不含有人DNA。序列分析表明人類Alu順序是由兩個約130bp的正向重複構成的二聚體,而在第二個單體中有一個31bp的插入序列,該插入序列在Alu家族的不同成員之間核苷酸順序相似但不相同。每個Alu順序兩側為6-20bp的正向重複順序,不同的Alu成員的側翼重複順序也各不相同。Alu序列的5'端比較保守,但富含脫氧腺苷酸殘基的3'端在不同的Alu成員中是有變化的。在相近的生物體中Alu家族在結構上存在相似性,一般認為靈長類基因組中的Alu順序多為由兩個130bp的正向重複組成的二聚體,而嚙類動物則為由一個130bp左右的DNA片段組成的單體。Alu序列在不同的哺乳動物之間存在著一定的相似性,但其序列相差較大,不會產生交叉雜交。Alu順序廣泛散佈於整個基因組的原因可能是由於Alu順序可由RNA聚合酶轉錄成RNA分子,再經反轉錄酶的作用形成cDNA,然後重新插入基因組所致。也有人認為Alu序列兩側存在著短的重複順序,使得Alu順序很象轉座子,因此推測Alu順序可能也是能夠移動的。這可能是它們在整個基因組中含量如此豐富,頒布如此廣泛的原因之一。Alu家族的功能是多方面的,由於在許多核內不均一RNA(hnRNA)中含有大量的Alu順序,而且,Alu順序含有與某些真核基因內含子剪接接頭相似的序列,因而,Alu順序可能參與hnRNA的加工與成熟。Alu序列在人基因組中不尋常地大量存在,提示它與遺傳重組及染色體不穩定性有關。最近發現在人的組織細胞中存在自然發生的染色體外雙鏈環狀DAN,被稱為人類質粒(human plasmid),而這些質粒又毫無例外地含有Alu順序。還有研究表明,Alu順序中的某些區段有形成Z-DNA的能力。另外,Alu順序可能具有轉錄調節作用。
KpnⅠ家族是中度重複順序中僅次於Alu家族的第二大家族。用限制性內切酶KpnⅠ消化人類及其它靈長類動物的DNA,在電泳譜上可以看到4個不同長度的片段,分別為1.2,1.5,1.8和1.9kb,這就是所謂的KpnⅠ家族。KpnⅠ家族成員順序比Alu家族更長(如人KpnⅠ順序長6.4kb),而且更加不均一,呈散在分佈,屬於中度重複順序的長分散片段型。儘管不同長度類型的KpnⅠ家族(稱為亞類,subfamily)之間同源性比較小,不能互相雜交,但它們的3'端有廣泛的同源性。KpnⅠ家族的拷貝數約為3000 ̄4800個,占人體基因組的1%,與散在分佈的Alu家族相似,KpnⅠ家族中至少有一部份也是通過KpnⅠ順序的RNA轉錄產物的cDNA拷貝的重新插入到人基因組DNA中而產生的。
這一家族以319bp長度的串聯重複存在於人體基因組中。用限制性內切酶HinfⅠ消化人體DNA,可以分離到這一片段。Hinf家族在單位基因組內約有50 100個拷貝,分散在不同的區域。319bp單位可以再分成兩個亞單位,分別為172bp和147bp,它們之間有70%的同源性。
這一家族的基本單位是dT-dG雙核苷酸,多個dT-dG雙核苷酸串聯重複在一起,分散於人體基因組中。已經發現,這個家族的一個成員位於人類δ和β珠蛋白基因之間,含有17個dT-dG雙核苷酸組成的串聯重複順序。在人基因組中,dT-dG交替順序達106拷貝,這些順序的平均長度為40bp。人們推測,這樣一個短的串聯重複順序可能是基因轉變(gene conversion)或不等交換(unequal crossing-over)的識別信號。另外,這些嘌呤和嘧啶的交替順序有助於Z-DNA的形成,在基因調節中可能起著重要的作用。中度重複順序除了包括以上非編碼區域外,許多編碼區如rRNA基因,tRNA基因,組蛋白基因等在基因組中也多次重複,屬於中度重複順序。
在原核生物如大腸桿菌基因組中,rRNA基因一共是七套;在真核生物中rRNA基因的重複次數更多。在真核生物基因組中18S和28S,rRNA基因是在同一轉錄單位中,低等的真核生物如酵母中,5SrRNA也和18S,28SrRNA在同一轉錄單位中;而在高等生物中,5SrRNA是單獨轉錄的,而且其在基因組中的重複次數高於18S和28S基因。和一般的中度重複順序不一樣,各重複單位中的rRNA基因都是相同的。rRNA基因通常集中成簇存在,而不是分散於基因組中,這樣的區域稱為rDNA,如染色體的核仁組織區(nucleolus organizer region)即為rDNA區。18S和28SrRNA基因構成一個轉錄單位。從轉錄單位上轉錄下來的rRNA前體經過酶切成為18S和28SrRNA。在哺乳動物和兩棲動物中,18S和28SrRNA之間一同被轉錄下來的間隔區經過加工成為5.8SrRNA(在大腸桿菌中該區含有tRNA序列)。rRNA前體的其它部份被降解成核苷酸。真核生物中每個轉錄單位約長7-8kb(在哺乳動物中長13kb),其中編碼rRNA的部份佔70-80%(哺乳動物中只佔50%左右)。一個rRNA基因簇(rDNA簇)含有許多轉錄單位,轉錄單位之間為不轉錄的間隔區,該間隔區由21-100bp片段組成的類似衛星DNA的串聯重複順序。轉錄單位和不轉錄的間隔區構成一個rDNA重複單位。由於不轉錄的間隔區中類似衛星DNA的串聯重複次數不一樣,因此,在不同生物及同種生物的不同rDNA重複單位之間不轉錄間隔區的長短相差甚大。非洲爪蟾的rDNA簇中,由類似衛星DNA的重複序列交替排列構成。5'端為一固定長度的獨特順序;後面的重複區域是由97bp的重複單位組成;另外兩個重複區域是由60bp或81bp的重複單位構成;由於每個重複區域中重複單位的重複次數在不同的rDNA重複單位中不一樣,因而造成不同的不轉錄間隔區的長短不一。另外兩個固定長度的區域稱為Bam島(因為這兩個片段的分離是採用BamHI酶消化製備的)。Bam島的後半部與轉錄單位前面的序列(含有啟動子)相似;另外在60/81bp的重複區域中也有類似的序列。根據這些結構特點,有人認為不轉錄的間隔區可能在轉錄單位的轉錄起始中起著重要作用。rDNA的重複單位在許多動物的卵子形成過程中進行大量複製擴增,如爪蟾在擴增前有rDNA重複單位500個,在從卵母細胞前身(oocyteprecursor)發展到卵母細胞過程中(3周時間),rDNA的重複單位可擴增400倍,每個細胞核的核仁數增加到幾百個。擴增rDNA的過程是採用滾環式複製方式在核仁區進行的,擴增的DNA不納入到染色體中,而是包含在核區。卵母細胞成熟后,大量的rDNA由於失去了存在的意義而逐漸降解。在卵子形成的過程中rDNA大量擴增的目的,就是為了產生大量的rRNA,組裝成核糖體,用於合成大量的蛋白質,以滿足受精后發育的需要。在大多數真核細胞中5SrRNA基因和18S,28SrRNA基因不屬於一個轉錄單位。5SrRNA基因在基因組中亦呈串聯重複排列成基因簇。其結構在非洲爪蟾中研究得最為清楚。在爪蟾體細胞中5SrRNA基因約有500拷貝,而在卵細胞中5S基因可重複20000多次。這大概是為了和卵細胞中大量擴增的28S和18S基因相統一。在爪蟾中發現有幾種5SrRNA基因。最主要的一種其結構形式與18S、28S基因相似,即5S基因與非轉錄間隔區相間排列,組成一個重複單位。每個重複單位的5'端是含有A-T豐富區的一段49bp長的G-C豐富區;下面跟是120bp的5SrRNA基因;後面又是一段 並不轉錄的序列,而且與前面的5S基因比較有9個點突變,因此稱為這段基因為假基因(pseudo gene)。儘管假基因不被轉錄,但在5S基因簇中總是有等量的5S基因和它的假基因。
在卵細胞中還有一個次要的5SrRNA基因,與主要的5S基因在序列上有一定和差異,在結構上與主要的5S基因相似,但整個重複單位長只有350bp,而且間隔區與主要的5S基因完全不一樣。
人類的rRNA基因位於13,14,15,21和22號染色體的核仁組織區,每個核仁組織區平均含有50個rRNA基因的重複單位。5SrRNA基因似乎全部位於1號染色體(1q42-43)上,每單倍體基因組約有1000個5SrRNA基因。tRNA基因的清確重複次數比較難以估計。在非洲爪蟾中約有300個拷貝由tRNAmet,tRNAphe,tRNATrp及其它tRNA基因組成的3.18kb的串聯重複單位。而在人體單倍基因組中約有1000-2000個tRNA基因,為50-60種rRNA編碼,每種平均重複20-30次。
組蛋白基因在各種生物體內重複的次數不一樣,但都在中度重複的範圍內。通常每種組蛋白的基因在同一種生物中拷貝數是相同的。雞的基因組中組蛋白基因有10個拷貝,在哺乳動物中為20拷貝,非洲爪蟾為40拷貝,而海膽的每種組蛋白的基因達300-600拷貝。不同生物中組蛋白基因在基因組中的排列不一樣,組蛋白基因沒有一定的排列方式,而在拷貝數高的基因組中(>100拷貝),大部份組蛋白基因串聯重複形成基因簇。
海膽發育早期五種組蛋白基形成一個重複單位,每種組蛋白基因之間是非轉錄間隔區,5個間隔區均不相同。這樣的重複單位在整個基因組中重複300次以上,而且這些重複單位基本上是相同的。在海膽中,5種組蛋白基因的轉錄方向都是相同的,每種組蛋白基因獨立的產生自己的mRNA。非洲爪蟾卵細胞5S基因重複單位包括一個基因和一個假基因。在三種不同的海膽中,其組蛋白基因重複單位中非轉錄間隔區在長度和序列上差異是很大的,儘管它們的組蛋白基因的長度和序列相差不多。實際上,在同一種海膽內不同的組蛋白基因重複單位之間,相應的非轉錄間隔區也不是完全相同的。另外,在海膽胚胎髮育晚期,要由晚期組蛋白基因來編碼組蛋白,該基因與上述的早期組蛋白基因有輕微的差異,但該組蛋白基因不成簇排列,整個基因組僅有10個拷貝,呈散在分佈。
在果蠅和非洲爪蟾中,5種組蛋白也排成一個重複單位,也存在間隔區,而且組蛋白基因的轉錄方向不一樣。多個重複單位也形成串聯重複排列。進化到哺乳動物,組蛋白基因一般不再形成重複單位,而呈散在分佈或集成一小群。儘管組蛋白基因在基因組中的排列和分佈在不同生物之間相差甚大,但是所有組蛋白基因都不含內含子,而且在序列上相應的組蛋白基因都很相似,從而編碼的組蛋白在結構上和功能上也極為相似。
基因組中存在大量重複序列用以編碼組蛋白是有其重要意義的。DNA複製時,組蛋白也要成倍增加,而且往往在DNA合成一小段后,組蛋白馬上就要與其相結合,這要求在較短的時間內合成大量的組蛋白,因而需要有大量的組蛋白基因存在。人體基因組中還有幾個大的基因簇,也屬於中度重複順序長的分散片段型。在一個基因簇內含有幾百個功能相關的基因,這些基因簇又稱為超基因(Super gene),如人類主要組織相容性抗原複合體HLA和免疫球蛋白重鏈及輕鏈基因都屬於超基因。超基因可能是由於基因擴增后又經過功能和結構上的輕微改變而產生的,但仍保留了原始基因的結構及功能的完整性。
(低度重複順序)
單拷貝順序在單倍體基因組中只出現一次或數次,因而復性速度很慢。單拷貝順序在基因組中佔50-80%,如人基因組中,大約有60-65%的順序屬於這一類。單拷貝順序中儲存了巨大的遺傳信息,編碼各種不同功能的蛋白質。目前尚不清楚單拷貝基因的確切數字,但是是有其在單拷貝順序中只有一小部份用來編碼各種蛋白質,其他部份的功能尚不清楚。
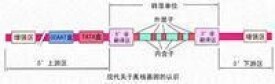
在基因組中,單拷貝順序的兩側往往為散在分佈的重複順序。由於某些單拷貝順序編碼蛋白質,體現了生物的各種功能,因此對這些序列的研究對醫學實踐有特別重要的意義。但由於其拷貝數少,在DNA重組技術出現以前,要分離和分析其結構和順序幾乎是不可能的,現在人們通過基因重組技術可以獲得大量欲研究的基因,並對許多結構基因進行了較為細緻的研究。現在已經知道,真核生物的結構基因不僅在兩側有非編碼區,而且在基因內部也有許多不編碼蛋白質的間隔序列(intervening sequences),稱為內含子(intron),而編碼區則稱為外顯子(exon)。內含子與外顯子相間排列,轉錄時一起被轉錄下來,然後RNA中的內含子被切掉,外顯子連接在一起成為成熟的mRNA作為指導蛋白質合成的模板)斷裂基因含有外顯子和內含子,轉錄成RNA后經過剪接切除內含子成熟為mRNA。
真核基因組的另一特點就是存在多基因家族(multi gene family)。多基因家族是指由某一祖先基因經過重複和變異所產生的一組基因。多基因家族大致可分為兩類:一類是基因家族成簇地分佈在某一條染色體上,它們可同時發揮作用,合成某些蛋白質,如組蛋白基因家族就成簇地集中在第7號染色體長臂3區2帶到3區6帶區域內;另一類是一個基因家族的不同成員成簇地分佈不同染色體上,這些不同成員編碼一組功能上緊密相關的蛋白質,如珠蛋白基因家族。在多基因家族中,某些成員並不產生有功能的基因產物,這些基因稱為假基因(pseudo gene)。假基因與有功能的基因同源,原來可能也是有功能的基因,但由於缺失,倒位或點突變等,使這一基因失去活性,成為無功能基因。與相應的正常基因相比,假基因往往缺少正常基因的內含子,兩側有順向重複序列。人們推測,假基因的來源之一,可能是基因經過轉錄後生成的RNA前體通過剪接失去內含子形成mRNA,如果mRNA經反覆轉錄產生cDNA,再整合到染色體DNA中去,便有可能成為假基因,因此該假基因是沒有內含子的,在這個過程中,可能同時會發生缺失,倒位或點突變等變化,從而使假基因不能表達。
在哺乳動物包括人體基因組中,存在著大量的非編碼順序,如前述的高度重複順序,內含子,間隔DNA等。這些順序中,只有很小一部份具有重要的調節功能,絕大部部分都沒有什麼特殊功用。在這些DNA序列中雖然積累了大量缺失,重複或其他突變,但對生物並沒有什麼影響,它們的功能似乎只是自身複製,所以人們稱這類DNA為自私DNA或寄生DNA(parasite DNA)。自私DNA也許有重要的功能,但目前我們還不了解。
基本信息
- 中文名
- 真核基因組
- 特點
- 存在重複序列等
- 內容對象
- 基因組
- 儲存位置
- 細胞核內