文本分類
文本分類
基於分類體系的自動分類
基於資訊過濾和用戶興趣(Profiles)的自動分類
所謂分類體系就是針對詞的統計來分類
關鍵字分類,現在的全文檢索
詞的正確切分不易分辨(白痴造句法)
學習人類對文本分類的知識和策略
從人對文本和類別之間相關性判斷來學習文件用字和標記類別之間的關聯
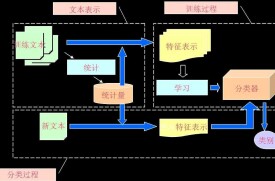
文本分類一般包括了文本的表達、分類器的選擇與訓練、分類結果的評價與反饋等過程,其中文本的表達又可細分為文本預處理、索引和統計、特徵抽取等步驟。文本分類系統的總體功能模塊為:
(1)預處理:將原始語料格式化為同一格式,便於後續的統一處理;
(2)索引:將文檔分解為基本處理單元,同時降低後續處理的開銷;
(3)統計:詞頻統計,項(單詞、概念)與分類的相關概率;
(4)特徵抽取:從文檔中抽取出反映文檔主題的特徵;
(5)分類器:分類器的訓練;
(6)評價:分類器的測試結果分析。
文本分類問題與其它分類問題沒有本質上的區別,其方法可以歸結為根據待分類數據的某些特徵來進行匹配,當然完全的匹配是不太可能的,因此必須(根據某種評價標準)選擇最優的匹配結果,從而完成分類。
詞匹配法是最早被提出的分類演演算法。這種方法僅根據文檔中是否出現了與類名相同的詞(頂多再加入同義詞的處理)來判斷文檔是否屬於某個類別。很顯然,這種過於簡單機械的方法無法帶來良好的分類效果。
後來興起過一段時間的知識工程的方法則藉助於專業人員的幫助,為每個類別定義大量的推理規則,如果一篇文檔能滿足這些推理規則,則可以判定屬於該類別。這 里與特定規則的匹配程度成為了文本的特徵。由於在系統中加入了人為判斷的因素,準確度比詞匹配法大為提高。但這種方法的缺點仍然明顯,例如分類的質量嚴重 依賴於這些規則的好壞,也就是依賴於制定規則的“人”的好壞;再比如制定規則的人都是專家級別,人力成本大幅上升常常令人難以承受;而知識工程最致命的弱 點是完全不具備可推廣性,一個針對金融領域構建的分類系統,如果要擴充到醫療或社會保險等相關領域,則除了完全推倒重來以外沒有其他辦法,常常造成巨大的 知識和資金浪費。
後來人們意識到,究竟依據什麼特徵來判斷文本應當隸屬的類別這個問題,就連人類自己都不太回答得清楚,有太多所謂“只可意會,不能言傳”的東西在裡面。人類的判斷大多依據經驗以及直覺,因此自然而然的會有人想到和讓機器像人類一樣自己來通過對大量同類文檔的觀察來自己總結經驗,作為今後分類的依據。這便是統計學習方法的基本思想。
統計學習方法需要一批由人工進行了準確分類的文檔作為學習的材料(稱為訓練集,注意由人分類一批文檔比從這些文檔中總結出準確的規則成本要低得多),計算機從這些文檔中挖掘出一些能夠有效分類的規則,這個過程被形象的稱為訓練,而總結出的規則集合常常被稱為分類器。訓練完成之後,需要對計算機從來沒有見過的文檔進行分類時,便使用這些分類器來進行。這些訓練集包括sogou文本分類分類測試數據、中文文本分類分類語料庫,包含Arts、Literature等類別的語料文本、可用於聚類的英文文本數據集、網易分類文本分類文本數據、tc-corpus-train(語料庫訓練集,適用於文本分類分類中的訓練)、2002年中文網頁分類訓練集CCT2002-v1.1等。
現如今,統計學習方法已經成為了文本分類領域絕對的主流。主要的原因在於其中的很多技術擁有堅實的理論基礎(相比之下,知識工程方法中專家的主觀因素居多),存在明確的評價標準,以及實際表現良好。統計分類演演算法
將樣本數據成功轉化為向量表示之後,計算機才算開始真正意義上的“學習”過程。常用的分類演演算法為:
決策樹,Rocchio,樸素貝葉斯,神經網路,支持向量機,線性最小平方擬合,kNN,遺傳演演算法,最大熵,Generalized Instance Set等。在這裡只挑幾個最具代表性的演演算法侃一侃。
Rocchio演演算法應該算是人們思考文本分類問題時最先能想到,也最符合直覺的解決方法。基本的思路是把一個類別里的樣本文檔各項取個平均值(例如把所有“體育”類文檔中辭彙“籃球”出現的次數取個平均值,再把“裁判”取個平均值,依次做下去),可以得到一個新的向量,形象的稱之為“質心”,質心就成了這 個類別最具代表性的向量表示。再有新文檔需要判斷的時候,比較新文檔和質心有多麼相像(八股點說,判斷他們之間的距離)就可以確定新文檔屬不屬於這個類。稍微改進一點的Rocchio演演算法不僅考慮屬於這個類別的文檔(稱為正樣本),也考慮不屬於這個類別的文檔數據(稱為負樣本),計算出來的質心盡量靠近正樣本同時盡量遠離負樣本。Rocchio演演算法做了兩個很致命的假設,使得它的性能出奇的差。一是它認為一個類別的文檔僅僅聚集在一個質心的周圍,實際情況往往不是如此(這樣的數據稱為線性不可分的);二是它假設訓練數據是絕對正確的,因為它沒有任何定量衡量樣本是否含有雜訊的機制,因而也就對錯誤數據毫無抵抗力。
不過Rocchio產生的分類器很直觀,很容易被人類理解,演演算法也簡單,還是有一定的利用價值的,常常被用來做科研中比較不同演演算法優劣的基線系統(Base Line)。
樸素貝葉斯演演算法
貝葉斯演演算法關注的是文檔屬於某類別概率。文檔屬於某個類別的概率等於文檔中每個詞屬於該類別的概率的綜合表達式。而每個詞屬於該類別的概率又在一定程度上 可以用這個詞在該類別訓練文檔中出現的次數(詞頻信息)來粗略估計,因而使得整個計算過程成為可行的。使用樸素貝葉斯演演算法時,在訓練階段的主要任務就是估計這些值。
樸素貝葉斯演演算法的公式並不是只有一個。
首先對於每一個樣本中的元素要計算先驗概率。其次要計算一個樣本對於每個分類的概率,概率最大的分類將被採納。所以
其中P(d| Ci)=P(w1|Ci) P(w2|Ci) …P(wi|Ci) P(w1|Ci) …P(wm|Ci) (式1)
P(w|C)=元素w在分類為C的樣本中出現次數/數據整理后的樣本中元素的總數(式2)
這其中就蘊含著樸素貝葉斯演演算法最大的兩個缺陷。
首先,P(d| Ci)之所以能展開成(式1)的連乘積形式,就是假設一篇文章中的各個詞之間是彼此獨立的,其中一個詞的出現絲毫不受另一個詞的影響(回憶一下概率論中變 量彼此獨立的概念就可以知道),但這顯然不對,即使不是語言學專家的我們也知道,詞語之間有明顯的所謂“共現”關係,在不同主題的文章中,可能共現的次數 或頻率有變化,但彼此間絕對談不上獨立。
其二,使用某個詞在某個類別訓練文檔中出現的次數來估計P(wi|Ci)時,只在訓練樣本數量非常多的情況下才比較準確(考慮扔硬幣的問題,得通過大量觀 察才能基本得出正反面出現的概率都是二分之一的結論,觀察次數太少時很可能得到錯誤的答案),而需要大量樣本的要求不僅給前期人工分類的工作帶來更高要求(從而成本上升),在後期由計算機處理的時候也對存儲和計算資源提出了更高的要求。
但是稍有常識的技術人員都會了解,數據挖掘中佔用大量時間的部分是數據整理。在數據整理階段,可以根據辭彙的情況生成字典,刪除冗餘沒有意義的辭彙,對於單字和重要的片語分開計算等等。
這樣可以避免樸素貝葉斯演演算法的一些問題。其實真正的問題還是存在於演演算法對於信息熵的計算方式。
樸素貝葉斯演演算法在很多情況下,通過專業人員的優化,可以取得極為良好的識別效果。最為人熟悉的兩家跨國軟體公司在目前仍採用樸素貝葉斯演演算法作為有些軟體自然語言處理的工具演演算法。
kNN演演算法
最近鄰演演算法(kNN):在給定新文檔后,計算新文檔特徵向量和訓練文檔集中各個文檔的向量的相似度,得到K篇與該新文 檔距離最近最相似的文檔,根據這K篇文檔所屬的類別判定新文檔所屬的類別(注意這也意味著kNN演演算法根本沒有真正意義上的“訓練”階段)。這種判斷方法很 好的克服了Rocchio演演算法中無法處理線性不可分問題的缺陷,也很適用於分類標準隨時會產生變化的需求(只要刪除舊訓練文檔,添加新訓練文檔,就改變了 分類的準則)。
kNN唯一的也可以說最致命的缺點就是判斷一篇新文檔的類別時,需要把它與現存的所有訓練文檔全都比較一遍,這個計算代價並不是每個系統都能夠承受的(比 如我將要構建的一個文本分類系統,上萬個類,每個類即便只有20個訓練樣本,為了判斷一個新文檔的類別,也要做20萬次的向量比較!)。一些基於kNN的 改良方法比如Generalized Instance Set就在試圖解決這個問題。
kNN也有另一個缺點,當樣本不平衡時,如一個類的樣本容量很大,而其他類樣本容量很小時,有可能導致當輸入一個新樣本時,該樣本的K個鄰居中大容量類的樣本佔多數。
SVM(Support Vector Machine)是Cortes和Vapnik於1995年首先提出的,它在解決小樣本、非線性及高維模式識別中表現出許多特有的優勢,並能夠推廣應用到函數擬合等其他機器學習問題中。
支持向量機方法是建立在統計學習理論的VC維理論和結構風險最小原理基礎上的,根據有限的樣本信息在模型的複雜性(即對特定訓練樣本的學習精度,Accuracy)和學習能力(即無錯誤地識別任意樣本的能力)之間尋求最佳折衷,以期獲得最好的推廣能力(或稱泛化能力)。
SVM 方法有很堅實的理論基礎,SVM 訓練的本質是解決一個二次規劃問題(Quadruple Programming,指目標函數為二次函數,約束條件為線性約束的最優化問題),得到的是全局最優解,這使它有著其他統計學習技術難以比擬的優越性。 SVM分類器的文本分類效果很好,是最好的分類器之一。同時使用核函數將 原始的樣本空間向高維空間進行變換,能夠解決原始樣本線性不可分的問題。其缺點是核函數的選擇缺乏指導,難以針對具體問題選擇最佳的核函數;另外SVM 訓練速度極大地受到訓練集規模的影響,計算開銷比較大,針對SVM 的訓練速度問題,研究者提出了很多改進方法,包括Chunking 方法、Osuna演演算法、SMO 演演算法和交互SVM 等。SVM分類器的優點在於通用性較好,且分類精度高、分類速度快、分類速度與訓練樣本個數無關,在查准和查全率方面都略優於kNN及樸素貝葉斯方法。
TMSVM:完整的基於Libsvm與Liblinear的文本分類系統,直接輸入訓練樣本,並配置相應參數,即可進行模型及預測。
1 F. Sebastiani. “Machine learning in automated text categorization.” ACM Computing Surveys, 34(1), pp. 1-47, 2002. (.pdf)
2 Aas K., Eikvil L.. Text Categorisation: A Survey. TechnicalReport. Norwegian Computing Center, Oslo, Norway,1999.
3 M. Rogati and Y. Yang. High-performing feature selection for text classification ACM CIKM 2002. (.pdf)
4 Tie-Yan Liu, Yiming Yang, Hao Wan, et al, Support Vector Machines Classification with Very Large Scale Taxonomy, SIGKDD Explorations, Special Issue on Text Mining and Natural Language Processing, vol.7, issue.1, pp36~43, 2005. (.pdf)
5 蘇金樹、張博鋒、徐 昕,基於機器學習的文本分類技術研究進展 軟體學報 17(9): 1848-1859, 2006.9 (.pdf)
6 基於統計學習理論的支持向量機演演算法研究
8 SVMlight
9 SVMTorch
基本信息
- 中文名
- 文本分類
- 支持語言
- 簡體中文
- 開發語言
- 英語
- 定義
- 基於分類體系的自動分類
- 類別
- 處理方式
- 方法
- 樸素貝葉斯、支持向量機、K鄰近法、決策樹