馬爾可夫決策過程
安德雷·馬爾可夫提出的概念
馬爾可夫決策過程是基於馬爾可夫過程理論的隨機動態系統的最優決策過程。馬爾可夫決策過程是序貫決策的主要研究領域。它是馬爾可夫過程與確定性的動態規劃相結合的產物,故又稱馬爾可夫型隨機動態規劃,屬於運籌學中數學規劃的一個分支。
在概率論和統計學中,馬可夫決策過程(英語:Markov Decision Processes,縮寫為 MDPs)提供了一個數學架構模型,用於面對部分隨機,部分可由決策者控制的狀態下,如何進行決策,以俄羅斯數學家安德雷·馬爾可夫的名字命名。在經由動態規劃與強化學習以解決最佳化問題的研究領域中,馬可夫決策過程是一個有用的工具。
馬爾可夫過程在概率論和統計學方面皆有影響。一個通過不相關的自變數定義的隨機過程,並(從數學上)體現出馬爾可夫性質,以具有此性質為依據可推斷出任何馬爾可夫過程。實際應用中更為重要的是,使用具有馬爾可夫性質這個假設來建立模型。在建模領域,具有馬爾可夫性質的假設是向隨機過程模型中引入統計相關性的同時,當分支增多時,允許相關性下降的少有幾種簡單的方式。
馬爾可夫決策過程是指決策者周期地或連續地觀察具有馬爾可夫性的隨機動態系統,序貫地作出決策。即根據每個時刻觀察到的狀態,從可用的行動集合中選用一個行動作出決策,系統下一步(未來)的狀態是隨機的,並且其狀態轉移概率具有馬爾可夫性。決策者根據新觀察到的狀態,再作新的決策,依此反覆地進行。馬爾可夫性是指一個隨機過程未來發展的概率規律與觀察之前的歷史無關的性質。馬爾可夫性又可簡單敘述為狀態轉移概率的無後效性。狀態轉移概率具有馬爾可夫性的隨機過程即為馬爾可夫過程。馬爾可夫決策過程又可看作隨機對策的特殊情形,在這種隨機對策中對策的一方是無意志的。馬爾可夫決策過程還可作為馬爾可夫型隨機最優控制,其決策變數就是控制變數。
50年代R.貝爾曼研究動態規劃時和L.S.沙普利研究隨機對策時已出現馬爾可夫決策過程的基本思想。R.A.霍華德(1960)和D.布萊克韋爾(1962)等人的研究工作奠定了馬爾可夫決策過程的理論基礎。1965年,布萊克韋爾關於一般狀態空間的研究和E.B.丁金關於非時齊(非時間平穩性)的研究,推動了這一理論的發展。1960年以來,馬爾可夫決策過程理論得到迅速發展,應用領域不斷擴大。凡是以馬爾可夫過程作為數學模型的問題,只要能引入決策和效用結構,均可應用這種理論。
馬爾可夫決策過程是一個五元組,其中
1) 是一組有限的狀態;
2) 是一組有限的行為(或者,是從狀態可用的有限的一組行動);
3) 是行動的概率 在狀態 在時間 會導致狀態 在時間 ;
4) 是從狀態轉移后得到的直接獎勵(或期望的直接獎勵);
5) 是折現係數,代表未來獎勵與現在獎勵之間的重要差異。
(註:馬爾可夫決策過程的理論並沒有說明這一點,或 是有限的,但是下面的基本演演算法假設它們是有限的)。
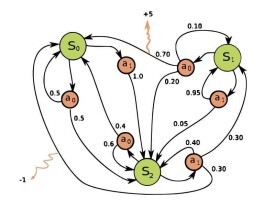
圖1表示具有三個狀態(綠色圓圈)和兩個動作(橙色圓圈)的簡單MDP的示例。
MDP的核心問題是為決策者找到一個 策略:一個功能指:決策者什麼時候會選擇行動。一旦馬爾可夫決策過程以這種方式與策略相結合,就可以解決每個狀態的行為,並且產生的組合行為就像一個馬爾可夫鏈。
由於馬爾可夫屬性,這個特定問題的最優策略確實可以寫成一個函數只有,如上所述。
對於連續時間的馬爾可夫決策過程,可以在決策者選擇的任何時候作出決定。與離散時間馬爾可夫決策過程相比,連續時間馬爾可夫決策過程可以更好地模擬連續動態系統的決策過程,即系統動力學由偏微分方程定義。
在離散時間馬爾科夫決策過程中,決策是在離散的時間間隔進行的。
策略是提供給決策者在各個時刻選取行動的規則,記作,其中 是時刻n選取行動的規則。從理論上來說,為了在大範圍尋求最優策略,最好根據時刻以前的歷史,甚至是隨機地選擇最優策略。但為了便於應用,常採用既不依賴於歷史、又不依賴於時間的策略,甚至可以採用確定性平穩策略。
衡量策略優劣的常用指標有折扣指標和平均指標。折扣指標是指長期折扣〔把時刻的單位收益摺合成0時刻的單位收益的 (β < 1)倍〕期望總報酬;平均指標是指單位時間的平均期望報酬。
採用折扣指標的馬爾可夫決策過程稱為 折扣模型。業已證明:若一個策略是 折扣最優的,則初始時刻的決策規則所構成的平穩策略對同一 也是折扣最優的,而且它還可以分解為若干個確定性平穩策略,它們對同一β都是最優的,已有計算這種策略的演演算法。
採用平均指標的馬爾可夫決策過程稱為 平均模型。已證明:當狀態空間 和行動集 均為有限集時,對於平均指標存在最優的確定性平穩策略;當 和 不是有限的情況,必須增加條件,才有最優的確定性平穩策略。計算這種策略的演演算法也已研製出來。
約束馬爾可夫決策過程(CMDPs)是馬爾可夫決策過程(MDPs)的擴展。MDP和CMDP有三個基本的區別。
1)應用時一個動作而不是一個動作需要多個成本;
2)CMDP只能通過線性程序來解決,動態編程不起作用;
3)最終的政策取決於開始的狀態。
CMDP有很多應用。它最近被用在機器人的運動規劃場景中。