模式識別系統
模式識別系統
模式識別系統基本上是由三部分組成,即數據採集、數據處理和分類決策或模型匹配。模式識別系統廣泛應用在語音識別、指紋識別、數字水印等領域。
一個完整的模式識別系統基本上是由三部分組成,即數據採集、數據處理和分類決策或模型匹配。在設計模式識別系統時,需要注意模式類的定義、應用場合、模式表示、特徵提取和選擇、聚類分析、分類器的設計和學習、訓練和測試樣本的選取、性能評價等。針對不同的應用目的, 模式識別系統三部分的內容可以有很大的差異, 特別是在數據處理和模式分類這兩部分,為了提高識別結果的可靠性往往需要加入知識庫(規則)以對可能產生的錯誤進行修正,或通過引入限制條件大大縮小識別模式在模型庫中的搜索空間,以減少匹配計算量。
模式識別系統基本由數據採集、數據處理和分類決策或抹胸匹配組成,他們的工作原理如下:
數據採集是利用用各種感測器把被研究對象的各種信息轉換為計算機可以接受的數值或符號串集合。習慣上,稱這種數值或符號串所組成的空間為模式空間。這一步的關鍵是感測器的選取。為了從這些數字或符號串中抽取出對識別有效的信息, 必須進行數據處理, 包括數字濾波和特徵提取。
數字濾波是為了消除輸入數據或信息中的雜訊,排除不相干的信號, 只留下與被研究對象的性質和採用的識別方法密切相關的特徵如表徵物體的形狀、周長、面積等等。在進行指紋識別時,指紋掃描設備採用合適的濾波演演算法, 如基於塊方圖的方向濾波、二值濾波等,過濾掉指紋圖像中不必要的部分。
特徵提取是指從濾波數據中衍生出有用的信息, 從許多特徵中尋找出最有效的特徵,以降低後續處理過程的難度。我們對濾波后的這些特徵進行必要的計算后,通過特徵選招環口提取或基元選擇形成模式的特徵空間。那麼,如何判斷什麼特徵是最有效的呢?人類很容易獲取的特徵,對於機器來說就很難獲取了,這就是模式識別中的特徵選擇與提取的問題。特徵選擇和提取是模式識別的一個關鍵問題。一般情況下,候選特徵種類越多,得到的結果應該越好。但是,由此可能會引發維數災害,即特徵維數過高,計算機難以求解。因此, 數據處理階段的關鍵是濾波演演算法和特徵提取方法的選取。不同的應用場合,採用的濾波演演算法和特徵提取方法以及提取出來的特徵也會不同。
基於數據處理生成的模式特徵空間,人們就可以進行模式識別的最後一部分模式分類或模型匹配。該階段最後輸出的可能是對象所屬的類型, 也可能是模型資料庫中與對象最相似的模式編號。
模式分類或描述通常是基於已經得到分類或描述的模式集合而進行的。人們稱這個模式集合為訓練集,由此產生的學習策略稱為監督學習。學習也可以是非監督性學習,在此意義下產生的系統不需要提供模式類的先驗知識,而是基於模式的統計規律或模式的相似性學習判斷模式的類別。
模式分類或模式匹配的方法很多,主要是基於以下思想設計的成員表,即模板匹配。基於該思想,分類系統中會預先存儲屬於同一模式類的模式集,然後將輸入的未知模式與系統中已有的模式相比較,具有相同或相似匹配的模式類即為該未知模式的所屬類型。一般特徵:這裡模式的一般特徵被存儲在一個分類系統中,當有一個未知模式進入該系統時,系統會將其一般特徵與系統中現有類的一般特徵相比較,並將其歸入到與其有相似特徵的類中。聚類文中筆者用實數向量來表示目標類的模式,這樣,利用其聚類特性,可以輕易地將未知模式進行分類。如果目標向量在幾何位置上相距很遠,就容易確定未知模式的類別。但是如果目標向量相距較近, 或甚至有重疊, 人們就需要採用比較複雜的演演算法來確定未知模式的類別。最小距離分類法就是一個基於聚類概念的重演演算法。該演演算法通過計算未知模式與希望的已知模式集之間的距離,來決定哪一個已知模式與該未知模式最近,並最終將該未知模式歸入到與其相距最短的已知模式類中。該演演算法對於目標向量在幾何位置上相距很遠的模式分類很有效。
神經元:上面的模式分類思想都是基於機器的直接計算,而直接計算則是基於數學相關的技術。仿生學是指將生物學知識應用到電子機器中。神經系統方法就是將生物知識應用於機器中來進行模式識別, 從而引進了人工神經元網路。一個神經元網路是一個信息處理系統,由大量簡單的數據處理單元組成,這些單元互相連接,協同工作,從而實現大規模并行分佈處理。神經元網路具有自適應學習、自組織和容錯力等優點由於這些突出特點,人們可以應用神經元網路進行模式識別。一些最好的神經元網路模型是後向傳播網路、高階網路、時延和周期性網路。通常,人們利用前向傳播網路進行模式識別。前向傳播也就是沒有回到輸入端的反饋信息。與人類從錯誤中得到教相似,神經元網路也能通過向輸入端反饋信息,從其錯誤中得到教訓。通過反饋可以重建輸入模式,避免產生錯誤,從而提高神經元網路的性能。當然,構造這樣的神經元網非常複雜。這類神經元網路要用到後向傳播演演算法(BP)。後向傳播演演算法的主要問題之一是局部極小問題。另外,神經元網路在學習速度、結構選擇、特徵表示、模塊性、縮放性等方面也都存在一些問題。雖然神經元網路存在這樣這樣那樣的問題和困難,但是其發展潛力還是巨大的。
語音識別技術正逐步成為信息技術中人機介面的關鍵技術,語音技術的應用已經成為一個具有競爭性的新興高技術產業。中國網際網路中心的市場預測,未來5年,中文語音技術領域將會有超過400億人民幣的市場容量,然後每年以超過的速度增長。
生物認證技術是本世紀最受關注的安全認證技術,它的發展是大勢所趨。人們願意忘掉所有的密碼、扔掉所有的磁卡,憑藉自身的唯一性來楊只身份與保密。在銀行里, 人們只需伸出手指放在識別儀上就可以存取現金將指日可待。國際數據集團(IDC)預測作為未來的必然發展方向的移動電子商務基礎核心技術的生物識別技術在未來10年的時間裡將達到美元的市場規模。
90年代以來才在國際上開始發展起來的數字水印技術是最具發展潛力與優勢的數字媒體版權保護技術。舊預測,數字水印技術在未來的年內全球市場容量超過80億美元。
卷積神經網路、深度殘差收縮網路等模式識別方法均被成功應用於旋轉機械的故障診斷。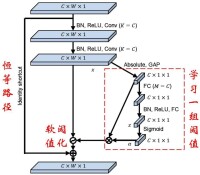
深度殘差收縮網路
基本信息
- 外文名
- pattern recognition system
- 應用
- 語音識別,生物認證等
- 簡稱
- PRS
- 組成
- 數據採集、數據處理和分類決策或模型匹配