隱馬可夫模型
探索看不到現象等的數學工具
隱馬可夫模型(Hidden Markov Model, HMM)是一連串事件接續發生的機率,用以探索看不到的世界/現象/事實的數學工具,是機器學習(Machine Learning)領域中常常用到的理論模型,從語音識別(Speech Recognition)、手勢辨識(gesture recognition),到生物信息學(Bioinformatics),都可以見到其身影。
我們通常都習慣尋找一個事物在一段時間裡的變化模式(規律)。
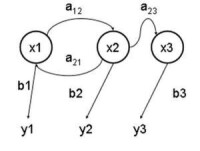
馬可夫鏈1
馬可夫鏈是一種具有狀態的隨機過程,從目前狀態轉移 s 到下一個狀態 s' 的機率由 q(s→s′) (或者 P(s′|s)) 所表示,這個狀態之轉移機率並不會受到狀態以外的因素所影響,因此與時間無關。通俗地說,就是同類型的事件(不同的狀態)依序發生的機率。
有人試圖通過一片海藻推斷天氣——民間傳說告訴我們‘濕透的’海藻意味著潮濕陰雨,而‘乾燥的’海藻則意味著陽光燦爛。
如果它處於一個中間狀態(‘有濕氣’),我們就無法確定天氣如何。然而,天氣的狀態並沒有受限於海藻的狀態,所以我們可以在觀察的基礎上預測天氣是雨天或晴天的可能性。
另一個有用的線索是前一天的天氣狀態(或者,至少是它的可能狀態)——通過綜合昨天的天氣及相應觀察到的海藻狀態,我們有可能更好的預測今天的天氣。
舉例
(1)假設今天是否下雨依賴於過去兩天的天氣情況。下雨時狀態為0,不下雨時狀態為1。
狀態 昨天 今天 明天
狀態0 1 1 0.7
狀態1 0 1 0.5
狀態2 1 0 0.4
狀態3 0 0 0.2
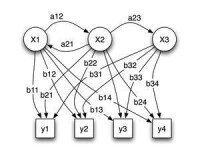
進一步詳細區分
Markov隨機過程具有如下的性質:在任意時刻,從當前狀態轉移到下一個狀態的概率與當前狀態之前的那些狀態沒有關係,即只與“現在”有關,而與“過去”無關。
假設我們有n個離散狀態S1, S2,…Sn,我們可以構造一個矩陣A,矩陣中的元素aij表示從當前狀態Si下一時刻遷移到Sj狀態的概率。
右圖: X 是隱含變數,Y 是可觀察變數,a 是轉換機率 (transition probabilities),b 是輸出概率 (output probabilities)
非確定性模式

非確定性模式
隱馬可夫模型即馬可夫鏈“隱藏”起來了,即:給出可觀察到的序列狀態,用它推測未知序列狀態。

隱馬可夫模型
如果把某人A每天從事的運動項目記錄下來(他“運動”這個事件的馬可夫鏈),那麼,我們可以根據某人A的運動情況去推測每天的天氣。在這個例子里,我們用能觀察得到的馬可夫鏈(某人A每天所從事的運動項目)去推測隱藏的馬可夫鏈(外面每天的天氣)的行為即為“隱馬可夫模型”,其是描述兩個或多個序列關係的統計模型。
柏拉圖的洞穴預言(Allegory of Cave),講的是“我們看到的世界”跟“真實的世界”的關係,恰好可以用來比喻一下隱馬可夫模型的作用。
馬可夫鏈是隨機變數的一個數列x,x,x,...。這些變數的範圍,即他們所有可能取值的集合,被稱為「狀態空間」,而x的值則是在時間n的狀態。如果xn+1對於過去狀態的條件機率分佈僅是xn的一個函數,則
P(x=x|x,x,x,...,x)=P(x=x|x)
這裡為過程中的某個狀態。上面這個恆等式可以被看作是馬可夫性質。
1. 針對已知的模型,計算某一特定輸出序列的概率:可使用 Forward Algorithm 或 Backward Algorithm 解決.
2. 針對已知的模型,尋找最可能的能產生某一特定輸出序列的隱含狀態的序列:可以使用 Viterbi Algorithm 解決.
3. 針對某輸出序列,尋找最可能的狀態轉移以及輸出概率:通常使用最大可能性法則 (Maximum Likelihood) 的演演演算法,像是 Baum-Welch algorithm (又稱為 Forward-backward Algorithm) 解決,此種演演演算法是 EM 演演演算法的一種特例。
假設你有一個朋友在外地,每天你可以通過電話來了解他每天的活動。他每天只會做三種活動之一——Walk, Shop, Clean。你的朋友從事哪一種活動的概率與當地的氣候有關,這裡,我們只考慮兩種天氣——Rainy, Sunny。我們知道,天氣與運動的關係如下:
| P(o|state) | Rainy | Sunny |
| Walk | 0.1 | 0.6 |
| Shop | 0.4 | 0.3 |
| Clean | 0.5 | 0.1 |
例如,在下雨天出去散步的可能性是0.1。
而天氣之前互相轉換的關係如下,(從行到列)
| p(state—>next_state) | Rainy | Sunny |
| Rainy | 0.7 | 0.3 |
| Sunny | 0.4 | 0.6 |
例如,從今天是晴天而明天就開始下雨的可能性是0.4 。
同時為了求解問題我們假設初始情況:通話開始的第一天的天氣有0.6的概率是Rainy,有0.4概率是Sunny。OK,現在的問題是,如果連續三天,你發現你的朋友的活動是:Walk->Shop->Clean(觀測序列);那麼,如何判斷你朋友那裡這幾天的天氣(隱藏狀態序列)是怎樣的?
解決這個問題的python偽代碼如下:
def forward_viterbi(y, X, sp, tp, ep):
T = {}
for state in X:
## prob. V. path V. prob.
T[state] = (sp[state], [state], sp[state])
for output in y:
U = {}
for next_state in X:
total = 0
argmax = None
valmax = 0
for source_state in X:
(prob, v_path, v_prob) = T[source_state]
p = ep[source_state][output] * tp[source_state][next_state]
prob *= p
v_prob *= p
total += prob
if v_prob > valmax:
argmax = v_path + [next_state]
valmax = v_prob
U[next_state] = (total, argmax, valmax)
T = U
## apply sum/max to the final states:
total = 0
argmax = None
valmax = 0
for state in X:
(prob, v_path, v_prob) = T[state]
total += prob
if v_prob > valmax:
argmax = v_path
valmax = v_prob
return (total, argmax, valmax)幾點說明:
演演算法對於每一個狀態要記錄一個三元組:(prob, v_path, v_prob),其中,prob是從開始狀態到當前狀態所有路徑(不僅僅
是最有可能的viterbi路徑)的概率加在一起的結果(作為演演算法附產品,它可以輸出一個觀察序列在給定HMM下總的出現概率,即forward演演算法的輸出),v_path是從開始狀態一直到當前狀態的viterbi路徑,v_prob則是該路徑的概率。
演演算法開始,初始化T (T是一個Map,將每一種可能狀態映射到上面所說的三元組上)三重循環,對每個一活動y,考慮下一步每一個可能的狀態next_state,並重新計算若從T中的當前狀態state躍遷到next_state概率會有怎樣的變化。躍遷主要考慮天氣轉移(tp[source_state][next_state])與該天氣下從事某種活動(ep[source_state][output])的聯合概率。所有下一步狀態考慮完后,要從T中找出最優的選擇viterbi路徑——即概率最大的viterbi路徑,即上面更新Map U的代碼U[next_state] = (total, argmax, valmax)。
演演算法最後還要對T中的各種情況總結,對total求和,選擇其中一條作為最優的viterbi路徑。
演演算法輸出四個天氣狀態,這是因為,計算第三天的概率時,要考慮天氣轉變到下一天的情況。
通過程序的輸出可以幫助理解這一過程:{p=p(observation|state)*p(state—>next_state)}
observation=Walk
next_state=Sunny
state=Sunny
p=0.36
triple=(0.144,Sunny->,0.144)
state=Rainy
p=0.03
triple=(0.018,Rainy->,0.018)
Update U[Sunny]=(0.162,Sunny->Sunny->,0.144)
next_state=Rainy
state=Sunny
p=0.24
triple=(0.096,Sunny->,0.096)
state=Rainy
p=0.07
triple=(0.042,Rainy->,0.042)
Update U[Rainy]=(0.138,Sunny->Rainy->,0.096)
observation=Shop
next_state=Sunny
state=Sunny
p=0.18
triple=(0.02916,Sunny->Sunny->,0.02592)
state=Rainy
p=0.12
triple=(0.01656,Sunny->Rainy->,0.01152)
Update U[Sunny]=(0.04572,Sunny->Sunny->Sunny->,0.02592)
next_state=Rainy
state=Sunny
p=0.12
triple=(0.01944,Sunny->Sunny->,0.01728)
state=Rainy
p=0.28
triple=(0.03864,Sunny->Rainy->,0.02688)
Update U[Rainy]=(0.05808,Sunny->Rainy->Rainy->,0.02688)
observation=Clean
next_state=Sunny
state=Sunny
p=0.06
triple=(0.0027432,Sunny->Sunny->Sunny->,0.0015552)
state=Rainy
p=0.15
triple=(0.008712,Sunny->Rainy->Rainy->,0.004032)
Update U[Sunny]=(0.0114552,Sunny->Rainy->Rainy->Sunny->,0.004032)
next_state=Rainy
state=Sunny
p=0.04
triple=(0.0018288,Sunny->Sunny->Sunny->,0.0010368)
state=Rainy
p=0.35
triple=(0.020328,Sunny->Rainy->Rainy->,0.009408)
Update U[Rainy]=(0.0221568,Sunny->Rainy->Rainy->Rainy->,0.009408)
final triple=(0.033612,Sunny->Rainy->Rainy->Rainy->,0.009408)所以,最終的結果是,朋友那邊這幾天最可能的天氣情況是Sunny->Rainy->Rainy->Rainy,它有0.009408的概率出現。而我們演演算法的另一個附帶的結論是,我們所觀察到的朋友這幾天的活動序列:Walk->Shop->Clean在我們的隱馬可夫模型之下出現的總概率是0.033612。
附:c++主要代碼片斷
void forward_viterbi(const vector & ob, viterbi_triple_t & vtriple)
{
//alias
map& sp = start_prob;
map > & tp = transition_prob;
map > & ep = emission_prob;
// initialization
InitParameters();
map T;
for (vector::iterator it = states.begin();
it != states.end();
++it)
{
viterbi_triple_t foo;
foo.prob = sp[*it];
foo.vpath.push_back(*it);
foo.vprob = sp[*it];
T[*it] = foo;
}
map U;
double total = 0;
vector argmax;
double valmax = 0;
double p = 0;
for (vector::const_iterator itob = ob.begin(); itob != ob.end(); ++itob)
{
cout << “observation=” << *itob << endl;
U.clear();
for (vector::iterator itNextState = states.begin();
itNextState != states.end();
++itNextState)
{
cout << “\tnext_state=” << *itNextState << endl;
total = 0;
argmax.clear();
valmax = 0;
for (vector::iterator itSrcState = states.begin();
itSrcState != states.end();
++itSrcState)
{
cout << “\t\tstate=” << *itSrcState << endl;
viterbi_triple_t foo = T[*itSrcState];
p = ep[*itSrcState][*itob] * tp[*itSrcState][*itNextState];
cout << “\t\t\tp=” << p << endl;
foo.prob *= p;
foo.vprob *= p;
cout << “\t\t\ttriple=” << foo << endl;
total += foo.prob;
if (foo.vprob > valmax)
{
foo.vpath.push_back(*itNextState);
argmax = foo.vpath;
valmax = foo.vprob;
}
}
U[*itNextState] = viterbi_triple_t(total, argmax, valmax);
cout << “\tUpdate U[" << *itNextState << "]=” << U[*itNextState] << “” << endl;
}
T.swap(U);
}
total = 0;
argmax.clear();
valmax = 0;
for (vector::iterator itState = states.begin();
itState != states.end();
++itState)
{
viterbi_triple_t foo = T[*itState];
total += foo.prob;
if (foo.vprob > valmax)
{
argmax.swap(foo.vpath);
valmax = foo.vprob;
}
}
vtriple.prob = total;
vtriple.vpath = argmax;
vtriple.vprob = valmax;
cout << “final triple=” << vtriple << endl;
}
馬可夫鏈通常用來建模排隊理論和統計學中的建模,還可作為信號模型用於熵編碼技術。
馬可夫鏈也有眾多的生物學應用,特別是增殖過程,可以幫助模擬生物增殖過程的建模。隱蔽馬可夫鏈還被用於生物信息學,用以編碼區域或基因預測。
馬可夫鏈最近的應用是在地理統計學中。其中,馬爾可夫鏈用在基於觀察數據的二到三維離散變數的隨機模擬。這一應用類似於“克里金”地理統計學(Kriging geostatistics),被稱為是“馬可夫鏈地理統計學”。
谷歌所使用的網頁排序演演算法(PageRank)就是由馬可夫鏈定義的。馬可夫模型也被應用於分析用戶瀏覽網頁的行為。
馬可夫過程,能為給定樣品文本,生成粗略,但看似真實的文本:他們被用於眾多供消遣的“模仿生成器”軟體。馬可夫鏈還被用於譜曲。
在語言學上,我們可以把人說話發出的聲音分成各種音節(syllable),語音是一連串的音節,而我們想要辨識成的文字,則是一連串的字。對語音識別系統而言,語音這個音節序列是看得到的訊號,而系統想要做的是推測出與其相對應的,看不到的文字序列,所以正好是 HMM 所模擬的狀況。
任何理論上可行的事情,必然伴隨著實務上的困難。理論上,我們如果有一段錄音,只要能分辨每一個音節發的音是哪些母音與子音,就能夠把這個人講的話辨識成文字;這種音節對應的工作看似容易,但是實際上會遇到很多模稜兩可的情況。以中文為例,兩個三聲的字連著念,前面的會讀成二聲,加上同音字、破聲字,同字的語音與讀音…等等,都增加了分辨過程的難度。
隱馬可夫模型在語音識別的的應用,大抵始於1970年代晚期的 IBM 計劃(Jelinek),時至今日,我們生活中可以看到的各種語音識別系統,例如Apple 的siri,Google的voice search,微軟前不久在北京展示的中英同步口譯,背後都是以HMM作為基礎技術。
生物信息學(bioinformatics)是另一個大量使用到 HMM 的領域,從DNA 序列的比對到演化歷程的推論,只要是跟基因序列有關的,幾乎都看得到 HMM 的應用。以DNA定序為例,一段採集到的DNA序列,包含了外顯子(exon)和內隱子(intron)兩種段落,兩者在細胞複製上有不同的功能,但都是由眾多的基因(gene,有A、T、C、G 4種)排列成的序列,因此在一串看得到的基因序列中,要如何標記出哪一段是外顯子,哪一段又是內隱子,這些看不到的段落,也是HMM可以發揮作用之處。簡單的說,外顯子和內隱子各自包含 A、T、C、G基因的比例不同,於是我們可以利用 HMM 相關的演演算法,找出哪一個基因是外顯子和內隱子的起點或終點。
0.7 0.3
P =
0.5 0.5
隱馬可夫模型當然也有它使用上的限制。例如,觀測與模擬的現象必須是序列(或者該說是馬可夫鏈),兩個序列之間的關係要夠明確等等,否則很容易就變成用十字螺絲起子去轉六角螺絲:或許可以運作,但是結果不盡然是原本想要的。