遺傳密碼
遺傳密碼
遺傳密碼又稱密碼子、遺傳密碼子、三聯體密碼。指信使RNA(mRNA)分子上從5'端到3'端方向,由起始密碼子AUG開始,每三個核苷酸組成的三聯體。
它決定肽鏈上每一個氨基酸和各氨基酸的合成順序,以及蛋白質合成的起始、延伸和終止。
遺傳密碼是一組規則,將DNA或RNA序列以三個核苷酸為一組的密碼子轉譯為蛋白質的氨基酸序列,以用於蛋白質合成。幾乎所有的生物都使用同樣的遺傳密碼,稱為標準遺傳密碼;即使是非細胞結構的病毒,它們也是使用標準遺傳密碼。但是也有少數生物使用一些稍微不同的遺傳密碼。
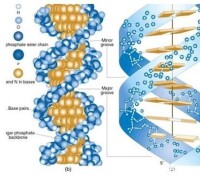
遺傳密碼決定蛋白質中氨基酸順序的核苷酸順序,由3個連續的核苷酸組成的密碼子所構成。由於脫氧核糖核酸(DNA)雙鏈中一般只有一條單鏈(稱為模版鏈)被轉錄為信使核糖核酸(mRNA),而另一條單鏈(稱為編碼鏈)則不被轉錄,所以即使對於以雙鏈 DNA作為遺傳物質的生物來講,密碼也用核糖核酸(RNA)中的核苷酸順序而不用DNA中的脫氧核苷酸順序表示。
大自然將奧秘或法則隱匿於一套密碼之中,藉此創作出數以千萬計的物種,之後又將其銷毀,終而復始,生生不息。
遺傳密碼
mRNA的讀碼方向從5'端至3'端方向,兩個密碼子之間無任何核苷酸隔開。mRNA鏈上鹼基的插入、缺失和重疊,均造成框移突變。
遺傳密碼錶
指一個氨基酸具有兩個或兩個以上的密碼子。密碼子的第三位鹼基改變往往不影響氨基酸翻譯。
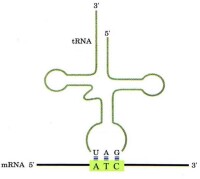
mRNA上的密碼子與轉移RNA(tRNA)J上的反密碼子配對辨認時,大多數情況遵守鹼基互補配對原則,但也可出現不嚴格配對,尤其是密碼子的第三位鹼基與反密碼子的第一位鹼基配對時常出現不嚴格鹼基互補,這種現象稱為擺動配對。
遺傳密碼
自從發現了DNA的結構,科學家便開始致力研究有關製造蛋白質的秘密。伽莫夫(George Gamow)指出需要以三個核酸一組才能為20個氨基酸編碼。1961年,美國國家衛生院的馬太(Heinrich Matthaei)與尼倫伯格(Marshall Warren Nirenberg)在無細胞系統(Cell-free system)環境下,把一條只由尿嘧啶(U)組成的RNA轉釋成一條只有苯丙氨酸(Phe)的多肽,由此破解了首個密碼子(UUU -> Phe)。隨後科拉納(Har Gobind Khorana)破解了其它密碼子,接著霍利(Robett W.Holley)發現了負責轉錄過程的tRNA。1968年,科拉納、霍利和尼倫伯格分享了諾貝爾生理學或醫學獎。
遺傳密碼
遺傳密碼
尼倫伯格等發現由三個核苷酸構成的微mRNA能促進相應的氨基酸-tRNA和核糖體結合。但微mRNA不能合成多肽,因此不一定可靠。科蘭納(Khorana,Har Gobind)用已知組成的兩個、三個或四個一組的核苷酸順序人工合成mRNA,在細胞外的轉譯系統中加入放射性標記的氨基酸,然後分析合成的多肽中氨基酸的組成。

尼倫伯格(Nirenberg,Marshall Warren)
後來,尼倫伯格等用多種不同的人工mRNA進行實驗,觀察所得多肽鏈上的氨基酸的類別,再用統計方法推算出人工mRNA中三聯體密碼出現的頻率,分析與合成蛋白中各種氨基酸的頻率之間的相關性,以此方法也能找出20種氨基酸的全部遺傳密碼。最後,科學家們還用了由3個核苷酸組成的各種多核苷鏈來檢查相應的氨基酸,進一步證實了全部密碼子。
DNA分子是由四種核苷酸的多聚體。這四種核苷酸的不同之處在於所含鹼基的不同,即A、T、C、G四種鹼基的不同。用A、T、C、G分別代表四種核苷酸,則DNA分子中將含有四種密碼符號。以一段DNA含有1000對核苷酸而言,這四種密碼的排列就可以有41000種形式,理論上可以表達出無限信息。
遺傳密碼
遺傳密碼(geneticcode)又是如何翻譯的呢?首先是以DNA的一條鏈為模板合成與它互補的mRNA,根據鹼基互補配對原則在這條mRNA鏈上,A變為U,T變為A,C變為G,G變為C。因此,這條mRNA上的遺傳密碼與原來模板DNA的互補DNA鏈是一樣的,所不同的只是U代替了T。然後再由mRNA上的遺傳密碼翻譯成多肽鏈中的氨基酸序列。鹼基與氨基酸兩者之間的密碼關係,顯然不可能是1個鹼基決定1個氨基酸。因此,一個鹼基的密碼子(codon)是不能成立的。如果是兩個鹼基決定1個氨基酸,那麼兩個鹼基的密碼子可能的組合將是42=16。這種比現存的20種氨基酸還差4種因此不敷應用。如果每三個鹼基決定一個氨基酸,三聯體密碼可能的組合將是43=64種。這比20種氨基酸多出44種,所以會產生多餘密碼子。可以認為是由於每個特定的氨基酸是由1個或多個的三聯體(triplet)密碼決定的。一個氨基酸由一個以上的三聯體密碼子所決定的現象,稱為簡併(degeneracy)。
每種三聯體密碼決定什麼氨基酸呢?從1961年開始,經過大量的實驗,分別利用64個已知三聯體密碼,找出了與他們對應的氨基酸。1966-1967年,全部完成了這套遺傳密碼的字典。大多數氨基酸都有幾個三聯體密碼,多則6個,少則2個,這就是上面提到過的簡併現象。只有色氨酸與甲硫氨酸這兩種氨基酸例外,只有1個三聯體密碼。此外,還有3個三聯體密碼UAA、UAG和UGA不編碼任何氨基酸,它們是蛋白質合成的終止信號。三聯體密碼AUG在原核生物中編碼甲醯化甲硫氨酸,在真核生物中編碼甲硫氨酸,並起合成起點作用。GUG編碼結氨酸,在某些生物中也兼有合成起點作用。分析簡併現象時可以看到,當三聯體密碼的第一個、第二個鹼基決定之後,有時不管第三個鹼基是什麼,都可能決定同一個氨基酸。例如,脯氨酸是由下列四個三聯體密碼決定的:CCU、CCC、CCA、CCG。也就是說,在一個三聯體密碼上,第一個,第二個鹼基比第三個鹼基更為重要,這就是產生簡併現象的基礎。
同義的密碼子越多,生物遺傳的穩定性越大。因為當DNA分子上的鹼基發生變化時,突變后所形成的三聯體密碼,可能與原來的三聯體密碼翻譯成同樣的氨基酸,或者化學性質相近的氨基酸,在多肽鏈上就不會表現任何變異或者變化不明顯。因而簡併現象對生物遺傳的穩定性具有重要意義。
除了少數的不同之外,地球上已知生物的遺傳密碼均非常接近;因此根據演化論,遺傳密碼應在生命歷史中很早期就出現。現有的證據表明遺傳密碼的設定並非是隨機的結果,對此有以下的可能解釋:
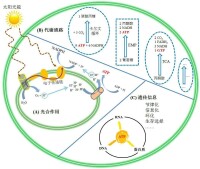
ATP在細胞中位於生化系統的中心
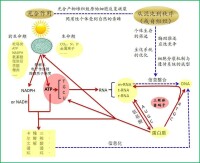
ATP中心假說示意圖
韋斯(Carl Richard Woese)認為,一些氨基酸與它們相對應的密碼子有選擇性的化學結合力(立體化學假說,stereochemical hypothesis),這顯示現在複雜的蛋白質製造過程可能並非一早存在,最初的蛋白質可能是直接在核酸上形成。但王子暉(J. Tze-Fei Wong)認為,氨基酸和相應編碼的忠實性反映了氨基酸生物合成路徑的相似性,並非物理化學性質的相似性(共進化假說,co-evolution hypothesis)。謝平指出,遺傳密碼子是生化系統的一部分,因 此,必須與生化系統的演化相關聯,而生化系統的核心是ATP,只有它才能建立起核酸和蛋白質之間的聯繫(ATP中心假說,ATP-centric hypothesis):ATP(a)是光能轉化成化學能的終端,(b)導演了一系列的生化循環(如卡爾文循環、糖酵解和三羧酸循環等)及元素重組,(c)它通過自身的轉化與縮合將錯綜複雜的生命過程信息化——篩選出用4種鹼基編碼20多個氨基酸的三聯體密碼子系統、精巧地構建了一套遺傳信息的保存、複製、轉錄和翻譯以及多肽鏈的生產體系,(d)演繹出蛋白質與核酸互為因果的反饋體系,在個體生存的方向性篩選中,構築了對細胞內成百上千種同步發生的生化反應進行秩序化管控(自組織)的複雜體系與規則,並最終建立起個性生命的同質化傳遞機制——遺傳。因此,遺傳密碼子的起源是原始生命從能量轉換到信息化的過程中實現的。
原始的遺傳密碼可能比今天簡單得多,隨著生命演化製造出新的氨基酸再被利用而令遺傳密碼變得複雜。雖然不少證據證明這一觀點,但詳細的演化過程仍在探索之中。經過自然選擇,現時的遺傳密碼減低了突變造成的不良影響。Knight等認為,遺傳密碼是由選擇(selection)、歷史(history)和化學(chemistry)三個因素在不同階段起作用的(綜合進化假說)。
其它假說:艾根提出了試管選擇(in vitro selection)假說,奧格爾(Leslie Eleazer Orgel)提出了解碼(decoding)機理起源假說,杜維(Christian de Duve)提出了第二遺傳密碼(second genetic code)假說。Wu等推測,三聯體密碼從兩種類型的雙聯體密碼逐漸進化而來, 這兩種雙聯體密碼是按照三聯體密碼中固定的鹼基位置來劃分的, 包括前綴密碼子(Prefix codons)和後綴密碼子(Suffix codons)。不過,Baranov等推測三聯體密碼子是從更長的密碼子(如四聯體密碼子quadruplet codons)演變而來,因為長的密碼子具有更多的編碼冗餘從而能抵禦更大的突變壓力。
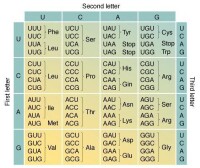
此表列出了64種密碼子以及氨基酸的標準配對。
第 一 位 鹼 基 | 第 二 位 鹼 基 | 第 三 位 鹼 基 | |||
| - | U | C | A | G | - |
| U | UUU (Phe/F)苯丙氨酸 UUC (Phe/F)苯丙氨酸 UUA (Leu/L)亮氨酸 UUG (Leu/L)亮氨酸 | UCU (Ser/S)絲氨酸 UCC (Ser/S)絲氨酸 UCA (Ser/S)絲氨酸 UCG (Ser/S)絲氨酸 | UAU (Tyr/Y)酪氨酸 UAC (Tyr/Y)酪氨酸 UAA (終止) UAG (終止) | UGU (Cys/C)半胱氨酸 UGC (Cys/C)半胱氨酸 UGA (終止) UGG (Trp/W)色氨酸 | U C A G |
| C | CUU (Leu/L)亮氨酸 CUC (Leu/L)亮氨酸 CUA (Leu/L)亮氨酸 CUG (Leu/L)亮氨酸 | CCU (Pro/P)脯氨酸 CCC (Pro/P)脯氨酸 CCA (Pro/P)脯氨酸 CCG (Pro/P)脯氨酸 | CAU (His/H)組氨酸 CAC (His/H)組氨酸 CAA (Gln/Q)谷氨醯胺 CAG (Gln/Q)谷氨醯胺 | CGU (Arg/R)精氨酸 CGC (Arg/R)精氨酸 CGA (Arg/R)精氨酸 CGG (Arg/R)精氨酸 | U C A G |
| A | AUU (Ile/I)異亮氨酸 AUC (Ile/I)異亮氨酸 AUA (Ile/I)異亮氨酸 AUG (Met/M)甲硫氨酸(起始) | ACU (Thr/T)蘇氨酸 ACC (Thr/T)蘇氨酸 ACA (Thr/T)蘇氨酸 ACG (Thr/T)蘇氨酸 | AAU (Asn/N)天冬醯胺 AAC (Asn/N)天冬醯胺 AAA (Lys/K)賴氨酸 AAG (Lys/K)賴氨酸 | AGU (Ser/S)絲氨酸 AGC (Ser/S)絲氨酸 AGA (Arg/R)精氨酸 AGG (Arg/R)精氨酸 | U C A G |
| G | GUU (Val/V)纈氨酸 GUC (Val/V)纈氨酸 GUA (Val/V)纈氨酸 GUG (Val/V)纈氨酸 | GCU (Ala/A)丙氨酸 GCC (Ala/A)丙氨酸 GCA (Ala/A)丙氨酸 GCG (Ala/A)丙氨酸 | GAU (Asp/D)天冬氨酸 GAC (Asp/D)天冬氨酸 GAA (Glu/E)谷氨酸 GAG (Glu/E)谷氨酸 | GGU (Gly/G)甘氨酸 GGC (Gly/G)甘氨酸 GGA (Gly/G)甘氨酸 GGG (Gly/G)甘氨酸 | U C A G |
註:(起始)標準起始編碼,同時為甲硫氨酸編碼。mRNA中第一個AUG就是蛋白質翻譯的起始部位。
此表列出了和20種氨基酸和密碼子的標準配對。
| Ala | A | GCU,GCC,GCA,GCG | Leu | L | UUA,UUG,CUU,CUC,CUA,CUG |
| Arg | R | CGU,CGC,CGA,CGG,AGA,AGG | Lys | K | AAA,AAG |
| Asn | N | AAU,AAC | Met | M | AUG |
| Asp | D | GAU,GAC | Phe | F | UUU,UUC |
| Cys | C | UGU,UGC | Pro | P | CCU,CCC,CCA,CCG |
| Gln | Q | CAA,CAG | Ser | S | UCU,UCC,UCA,UCG,AGU,AGC |
| Glu | E | GAA,GAG | Thr | T | ACU,ACC,ACA,ACG |
| Gly | G | GGU,GGC,GGA,GGG | Trp | W | UGG |
| His | H | CAU,CAC | Tyr | Y | UAU,UAC |
| Ile | I | AUU,AUC,AUA | Val | V | GUU,GUC,GUA,GUG |
| 起始 | AUG | 終止 | UAG,UGA,UAA |
起始和終止密碼子
遺傳密碼
在經典遺傳學中,終止密碼子各有名稱:UAG為琥珀(amber),UGA為蛋白石(opal),UAA為赭石(ochre)。這些名稱來源於最初發現到這些終止密碼子的基因的名稱。終止密碼子使核糖體和釋放因子結合,使多肽從核糖體分離而結束轉譯的程序。另外,在哺乳動物的線粒體中,AGA和AGG也充當終止密碼子。
簡併性
大部分密碼子具有簡併性,即兩個或者多個密碼子編碼同一氨基酸。簡併的密碼子通常只有第三位鹼基不同,例如,GAA和GAG都編碼谷氨醯胺。如果不管密碼子的第三位為哪種核苷酸,都編碼同一種氨基酸,則稱之為四重簡併;如果第三位有四種可能的核苷酸之中的兩種,而且編碼同一種氨基酸,則稱之為二重簡併,一般第三位上兩種等價的核苷酸同為嘌呤(A/G)或者嘧啶(C/T)。只有兩種氨基酸僅由一個密碼子編碼,一個是甲硫氨酸,由AUG編碼,同時也是起始密碼子;另一個是色氨酸,由UGG編碼。遺傳密碼的這些性質可使基因更加耐受點突變。例如,四重簡併密碼子可以容忍密碼子第三位的任何變異;二重簡併密碼子使三分之一可能的第三位的變異不影響蛋白質序列。由於轉換變異(嘌呤變為嘌呤或者嘧啶變為嘧啶)比顛換變異(嘌呤變為嘧啶或者嘧啶變為嘌呤)的可能性更大,因此二重簡併密碼子也具有很強的對抗突變的能力。不影響氨基酸序列的突變稱為沉默突變。
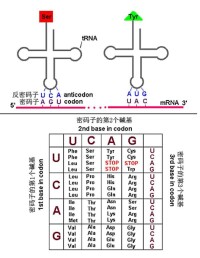
三聯體密碼錶以及tRNA的反密碼子與mRNA的密碼子的配對
另一種有助對抗點突變的情況,是NUN (N代表任何核苷酸)傾向於代表疏水性氨基酸,故此即使出現突變,仍有較大機會維持蛋白質的親水度,減低致命破壞的可能。
閱讀框
“密碼子”是由閱讀的起始位點決定的。例如,一段序列GGGAAACCC,如果由第一個位置開始讀,包括3個密碼子GGG,AAA和CCC。如果從第二位開始讀,包括GGA和AAC(忽略不完整的密碼子)。如果從第三位開始讀,則為GAA和ACC。故此每段序列都可以分為三個閱讀框,每個都能產生不同的氨基酸序列(在上例中,相應為Gly-Lys-Pro,Gly-Asp,和Glu-Thr)。而因為DNA的雙螺旋結構,每段DNA實際上有六個閱讀框。實際的框架是由起始密碼子確定,通常是mRNA序列上第一個出現的AUG。破壞閱讀框架的變異(例如,插入或刪除1個或2個核苷酸)稱為閱讀框變異,通常會嚴重影響到蛋白質的功能,故此並不常見,因為他們通常不能在演化中存活下來。
非標準的遺傳密碼
雖然遺傳密碼在不同生命之間有很強的一致性,但亦存在非標準的遺傳密碼。在有“細胞能量工廠”之稱的線粒體中,便有和標準遺傳密碼數個相異的之處,甚至不同生物的線粒體有不同的遺傳密碼。支原體會把UGA轉譯為色氨酸。纖毛蟲則把UAG(有時候還有UAA)轉譯為谷氨醯胺(一些綠藻也有同樣現象),或把UGA轉譯為半胱氨酸。一些酵母會把GUG轉譯為絲氨酸。在一些罕見情況,一些蛋白質會有AUG以外的起始密碼子。真菌、原生生物和人以及其它動物的粒線體中的遺傳密碼與標準遺傳密碼的差異,主要變化如下:
| 密碼子 | 通常的作用 | 例外的作用 | 所屬的生物 |
| UGA | 中止編碼 | 色氨酸編碼 | 人、牛、酵母線粒體,支原體(Mycoplasma)基因組,如Capricolum |
| UGA | 中止編碼 | 半胱氨酸編碼 | 一些纖毛蟲(ciliate)細胞核基因組,如游纖蟲屬(Euplotes) |
| AGR | 精氨酸編碼 | 中止編碼 | 大部分動物線粒體,脊椎動物線粒體 |
| AGA | 精氨酸編碼 | 絲氨酸編碼 | 果蠅線粒體 |
| AUA | 異亮氨酸編碼 | 蛋氨酸編碼 | 一些動物和酵母線粒體 |
| UAA | 中止編碼 | 谷氨醯胺編碼 | 草履蟲、一些纖毛蟲(ciliate)細胞核基因組,如嗜熱四膜蟲(ThermophAilus tetrahymena) |
| UAG | 中止編碼 | 谷氨酸編碼 | 草履蟲核細胞核基因組 |
| GUG | 纈氨酸編碼 | 絲氨酸編碼 | 假絲酵母核基因組 |
| AAA | 賴氨酸編碼 | 天冬氨酸編碼 | 一些動物的線粒體,果蠅線粒體 |
| CUG | 亮氨酸編碼 | 中止編碼 | 圓柱念珠菌(Candida cylindracea)細胞核基因組 |
| CUN | 亮氨酸編碼 | 蘇氨酸編碼 | 酵母線粒體 |
按信使RNA的序列,在一些蛋白質里停止密碼子會被翻譯成非標準的氨基酸,例如UGA轉譯為硒半胱氨酸和UAG轉譯為吡咯賴氨酸,隨著對基因組序列加深了解,科學家可能還會發現其它非標準的轉譯方式,以及其它未知氨基酸在生物中的應用。
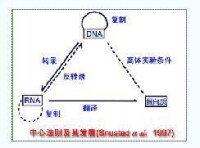
一個生物體攜帶的全套遺傳信息,即基因組。具體化學分子是DNA線狀分子。分子中每個有功能的單位被稱作基因,每個基因均是由一連串單核苷酸組成。能編碼蛋白質的基因稱為結構基因。結構基因的表達是DNA分子通過轉錄反應生成線狀核酸RNA分子,RNA分子在翻譯系統的作用下翻譯成蛋白質。
每個單核苷酸均由鹼基,戊糖(即五碳糖,DNA中為脫氧核糖,RNA中為核糖)和磷酸三部分組成。鹼基不同構成了不同的單核苷酸。組成DNA的鹼基有腺嘌呤(A),鳥嘌呤(G),胞嘧啶(C)及胸腺嘧啶(T)。組成RNA的鹼基以尿嘧啶(U)代替了胸腺嘧啶(T)。
三個單核苷酸形成一組密碼子,而每個密碼子代表一個氨基酸或終止信號。
在蛋白質合成的過程中,基因先被從DNA轉錄為對應的RNA模板,即信使RNA(mRNA)。接下來在核糖體和轉移RNA(tRNA)以及一些酶的作用下,由該RNA模板轉譯成為氨基酸組成的鏈(多肽),然後經過翻譯后修飾形成蛋白質。
因為密碼子由三個核苷酸組成,故一共有43=64種密碼子。例如,RNA序列UAGCAAUCC包含了三個密碼子:UAG,CAA和UCC。這段RNA編碼了代表了長度為3個氨基酸的一段蛋白質序列。(DNA也有類似的序列,但是以T代替了U)。
遺傳密碼是由核苷酸組成的三聯體。翻譯時從起始密碼子開始,沿著mRNA的5′——3′方向,不重疊地連續閱讀氨基酸密碼子,一直進行到終止密碼子才停止,結果從N端到C端生成一條具有特定順序的肽鏈。
“遺傳密碼”一詞,現在被用來代表兩種完全不同的含義,外行常用它來表示生物體內的全部遺傳信息。分子生物學家指的是表示四個字母的核酸語言和20個字母的蛋白質語言之間關係的小字典。要了解核苷酸順序是如何決定氨基酸順序的,首先要知道編碼的比例關係,即要弄清楚核苷酸數目與氨基酸數目的對應比例關係。
從數學觀點考慮,核酸通常有四種核苷酸,而組成蛋白質的氨基酸有20種,因此,一種核苷酸作為一種氨基酸的密碼是不可能的。如果兩種核苷酸為一組,代表一種氨基酸,那麼它們所能代表的氨基酸也只能有42=16種(不足20種)。如果三個核苷酸對應一個氨基酸,那麼可能的密碼子有43=64種,這是能夠將20種氨基酸全部包括進去的最低比例。因此密碼子是三聯體(triplet),而不是二聯體,(duplet),更不是單一體(singlet)。
國際公認的遺傳密碼,它是在1954年首先由蓋莫夫提出具體設想,即四種不同的鹼基怎樣排列組合進行編碼,才能表達出20種不同的氨基酸。1961年,由尼倫伯格等用大腸桿菌無細胞體系實驗,發現苯丙氨酸的密碼就是RNA上的尿嘧啶UUU密碼子,到1966年,64種遺傳密碼全部破譯。
在64個密碼子中,一共有三個終止密碼子,它們是UAA、UAG和UGA,不與tRNA結合,但能被釋放因子識別。終止密碼子也叫標點密碼子或叫無意義密碼子。有兩個氨基酸密碼子AUG和GUG同時兼作起密碼子,它們作為體內蛋白質生物合成的起始信號,其中AUG使用最普遍。
密碼的最終破譯是由實驗室而不是由理論得出的,遺傳密碼體現了分子生物學的核心,猶如元素周期表是化學的核心一樣,但二者又有很大的差別。元素周期表很可能在宇宙中的任何地方都是正確的,特別是在溫度和壓力與地球都相似的條件下。但是如果在其他星球也有生命的存在,而那種生命也利用核酸和蛋白質,它們的密碼很可能有巨的差異。在地球上,遺傳密碼只在某些生物中有微小的變異。克里克認為,遺傳密碼如同生命本身一樣,並不是事物永恆的性質,至少在一定程度上,它是偶然的產物。當密碼最初開始進化的,它很可能對生命的起源起重要作用。
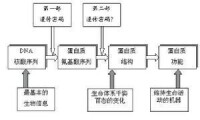
對生命遺傳信息存儲傳遞及表達的認識是20世紀生物學所取得的最重要的突破。其中的關鍵問題是由3個相連的核苷酸順序決定蛋白質分子肽鏈中的1個氨基酸,即“三聯遺傳密碼”(‘第一遺傳密碼“)的破譯。但是蛋白質必須有特定的三維空間結構,才能表現其特定的生物功能。50年代Anfinsen提出假說,認為蛋白質特定的三維空間結構是由其氨基酸排列順序所決定的,並因此獲得諾貝爾獎。這一論斷現在已被廣泛接受,大量實驗充分說明氨基酸
順序與蛋白質空間結構之間確實存在著一定的關係。遺傳信息的傳遞,應該是從核酸序列到功能蛋白質的全過程。現有的遺傳密碼僅有從核酸序列到無結構的多肽鏈的信息傳遞,因此是不完整的。本文討論的是從無結構的多肽鏈到
有完整結構的功能蛋白質的信息傳遞部分。完整的提法應該是遺傳密碼的第二部分,即蛋白質中氨基酸序列與其空間結構的對應關係,國際上稱之為第二遺傳密碼或摺疊密碼(以下簡稱第二密碼)。Anfinsen原理認為,和一定的氨基酸序列相對應的空間結構是熱力學上最穩定的結構,但多肽鏈摺疊成為相應的空間結構在實際上還存在一個“這一過程是否能夠在一定時間內完成”的動力學問題。事實上蛋白質最穩定結構與一些相似結構之間的能量差並不大,約在20.9~83.7kJ/mol左右。
蛋白質之所以最容易形成天然結構除能量因素外,是由動力學和熵的因素所決定的。近10餘年來國際上在蛋白質天然結構形成的問題上發生了概念上的變革。過去曾經認為新生肽鏈能夠自發地摺疊成為完整的空間結構,分子伴侶的發現已經把過去經典的自發摺疊概念轉變為,有幫助的肽鏈的自發摺疊和組裝“的新概念”。“自發”是指由第二遺傳密碼決定摺疊終態的“內因”亦即熱力學因素,而“幫助”則是為保證該過程能高效完成的“外因”,是由一類新發現的分子伴侶蛋白和摺疊酶來幫助完成的,主要是幫助克服動力學和熵的障礙,因而幫助克服細胞內由各種因素引起摺疊錯誤並造成翻譯后多肽鏈分子的聚集沉澱而最終導致信息傳遞中止。新生肽成熟為活性蛋白的過程中,不僅有摺疊中間體與分子伴侶和摺疊酶的相互作用,還有亞基間相互作用而組裝成有功能的多亞基蛋白,以及錯誤摺疊分子與特異蛋白水解酶的識別和作用以從細胞內清除構象錯誤的分子等。細胞內摺疊過程也是一個蛋白分子內和分子間肽鏈相互作用的過程。細胞內新合成的多肽鏈濃度極高,這種“擁擠”狀態會加劇蛋白分子間的錯誤相互作用而導致分子聚集。
人類基因圖譜的遺傳密碼序列最近即將全部揭曉,科學家大膽地預測醫學即將進入分子醫學與基因治療的時代,我們不僅可以利用分子醫學或生物晶片的方法,找出有問題的致病分子,利用基因工程的方法加以改造,進行所謂“基因治療“,還可以分析某某人的全部遺傳密碼序列,提前預測將來發生某種疾病的傾向。一切似乎非常完美,真的是如此嗎?
臨床的疾病,真正屬於單一基因發生突變的仍屬少數,大部分的疾病依舊原因不明,據推測多基因(Polygenic)或多因子(Polyfactorial)的原因佔了大宗。單基因的疾病,例如苯酮尿症(Phenylketonuria)、舞蹈症(Huntington’sChorea)、地中海型貧血(beta-Thalassemia)等只佔了很小的比例,常見的疾病,例如高血壓、糖尿病、退化性關節炎、老人失智症,可能是好幾個基因出了問題,加上環境的因素的影響。對於單基因的疾病,現在可以應用遺傳連鎖(Linkagestudy)的方法,將致病基因定位(Positionalcloning),再破解遺傳密碼,但是多基因或多因子造成的疾病,目前並沒有可行的遺傳學理論或實驗方法,可以用來找到所有可能相關的基因。
因為受到醫學倫理的約束,基因治療的臨床價值迄今仍未得到證明。基因治療最早是針對ADA(Adenosinedeaminase)缺乏引起的免疫缺乏症(泡泡娃娃,Bubblebaby),由美國國家衛生院的FrancisAnderson等人主持,他們取出病人的骨髓細胞,用基因工程的技術加以改造,修補其免疫缺損,再重新輸回病人的身體,基因治療的同時,病人也接受ADA酵素的治療,研究人員擔心萬一基因治療無效,因此不敢貿然停止ADA的使用,基因治療究竟是否有效,並沒有客觀的結論。
1980年代有學者在國際知名的Nature雜誌上發表研究論文,指出精神分裂症及躁鬱症與遺傳的關係,精神分裂症的基因被定位於第五對染色體,躁鬱症的基因則位於第十一對染色體,後來相關的研究並不能重複這些結果,因此早先發表的文章遭到撤回,試想高血壓,糖尿病究竟是單基因、多基因、或者環境因素所造成,迄今仍原因未明,更何況這些複雜的精神疾病!
人類行為的遺傳模式到現在仍不清楚,大部分精神分裂症及躁鬱症的病人都是偶發的個案,偶而有家族史,但是很少有三代以上的家族病史,無法套用目前基因連鎖定位(Linkagestudy)來做致病基因的染色體定位;大部分的病人多半在二十歲左右發病,不容易找到對象結婚,因此精神疾病如果完全是由於遺傳基因的作用,他們的遺傳基因也很難傳遞到下一代,但是人口中精神分裂症及躁鬱症的病人所佔的比例始終約略小於百分之一,這種現象很難以現有的遺傳學理論解釋;精神疾病目前診斷的方式,仍然以癥狀診斷為主,始終缺乏生物性的診斷方法,譬如抽血檢查血液中的化學物質,或者影像學的檢查,看看腦部那個結構出了問題;精神疾病的異質性(Heterogenecity)相當高,增加研究的困難度,很難區分究竟是先天遺傳或者後天環境造成。
1980年代曾有學者以美國東部Amish族群作為研究躁鬱症的對象,後來因為少數幾個個案的診斷有疑義,整的研究結果受到質疑。自從Watson及Crick於1953年發表DNA的論文之後,分子生物學一日千里,經由國際上許多科學家的協同努力,今天終於揭開人類的遺傳密碼序列,但是行為科學與精神醫學連入口在哪裡,現在都還不知道,之所以如此艱難,是因為到目前為止,連最基本的心智功能都沒有明確的定義,更遑論要整合各種研究的結論,例如記憶(Memory)就有好多種分法,譬如分成即時記憶、短程記憶及長程記憶,也可分為明確記憶(Explicitmemory)及隱含記憶(Implicitmemory),加上工作狀態記憶(Workingmemory)等等;大腦可以記憶,小腦也有記憶能力,例如開車,遇到緊急狀況踩煞車,通常是反射動作,不經過大腦考慮,單單對於記憶的了解就如此凌亂,其他如情緒、知覺、理解力、邏輯推理能力等等,迄今仍是渾沌一片。
樂觀的看來,最近這十年,或者最近這一百年,不會有太大進展,悲觀的一派則認為人類的心智永遠沒有解答,除非遺傳學以及神經科學理論的基本架構有劃時代突破性的發現。
第一密碼的闡明解決了基因在不同生物體之間的轉移與表達,開闢了遺傳工程和蛋白工程的新產業。但是在異體表達的蛋白質往往不能正確摺疊成為活性蛋白質而聚集形成包含體。生物工程的這個在生產上的瓶頸問題需要第二密碼的理論研究和摺疊的實驗研究來指導和幫助解決。由於分子伴侶在新生肽鏈摺疊中的關鍵作用,它一定會對提高生物工程產物的產率有重要的實用價值。
蛋白工程的興起,已經使人們不再滿足於天然蛋白的利用,而開始追求設計自然界不存在的全新的具有某些特定性質的蛋白質,這就開闢了蛋白設計的新領域。前面提到的把原來主要是β-摺疊結構改變為一個主要是α-螺旋的新蛋白的設計就是這方面的一個例子,更多的努力將集中於有實用意義的蛋白設計上。近年來得知某些疾病是由於蛋白質摺疊錯誤而引起的如類似於瘋牛病的某些神經性疾病老年性痴呆症帕金森氏症。這已引起人們極大的注意。異常刺激會誘導細胞立即合成大量應激蛋白幫助細胞克服環境變化,這些應激蛋白多半是分子伴侶。由於分子伴侶
在細胞生命活動的各個層次和環節上都有重要的甚至關鍵的作用,它們的表達和行為必然與疾病有密切關係。如局部缺血化療損傷心臟擴大高燒炎症感染代謝病細胞和組織損傷以及老年化都與應激蛋白有關。因此在醫學上不僅開闢了與分子伴侶和應激蛋白有關的新的研究領域,也開創了廣闊的應用前景。
基本信息
- 中文名
- 遺傳密碼
- 外文名
- genetic code