蛋白質組研究
蛋白質組研究
蛋白質組研究本質上指的是在大規模水平上研究蛋白質的特徵,包括蛋白質的表達水平,翻譯后的修飾,蛋白與蛋白相互作用等,由此獲得蛋白質水平上的關於疾病發生,細胞代謝等過程的整體而全面的認識,這個概念最早是在1995年提出的。蛋白質組的研究不僅能為生命活動規律提供物質基礎,也能為眾多種疾病機理的闡明及攻克提供理論根據和解決途徑。
蛋白質組
蛋白質組學研究
任何一種生物的基因組,都是由不編碼蛋白質的核苷酸序列和編碼蛋白質的核苷酸序列(基因)所組成。基因通常只是基因組的一小部分,例如編碼人類蛋白質的核苷酸序列大約佔人類基因組的2%。要想從混雜有大量非編碼核苷酸序列的基因組中找出基因,如同沙裡淘金。基因組研究的結果表明,一個基因組擁有的“基因”數目是由兩部分組成的:通過實驗證明確有蛋白質產物的真實基因、根據起始密碼和終止密碼序列所確定的潛在基因。生物學家們把這兩類基因都稱為“開放閱讀框”(open reading frame,ORF)。因此,一個基因組內的基因數目通常是指ORF的數目。
當一個基因組的全序列測定之後,確定其含有的ORF就成為了主要任務,稱為基因註釋。目前用於基因註釋的方法還有較高的出錯率,尤其對於那些存在不連續基因(即在一個基因內插有非編碼的核苷酸序列)的複雜基因組,出錯的問題更為突出。此外,這些ORF是否與蛋白質存在一一對應關係也是一個問題。一方面,人們已經發現有許多“假基因”(pseudogene)的存在,這些假基因有和真基因相同的ORF,但卻從不表達。另一方面,由於存在RNA水平上遺傳信息的加工——mRNA編輯(RNA editing),以及蛋白質水平上遺傳信息的加工——蛋白質剪接(protein splicing),許多蛋白質很難找到直接對應的ORF。如果我們不能確定基因組的“所有”基因,我們從何知道蛋白質組的“全部”蛋白質?
顯然,確定基因數目最可靠的方法是通過研究蛋白質組來進行。據最新統計,人類基因組擁有的基因數目大約是在3萬到4萬個之間。如果能夠把人體252種細胞內的全部蛋白質都給鑒定出來,那麼我們就有可能真正知道人類基因組的所有基因。但是這樣一來,基因組和蛋白質組形成了“循環定義”:蛋白質組是以基因組擁有的所有基因的表達產物來構成,而所有基因的確定又必須通過蛋白質組來給予肯定。
蛋白質組學的研究技術目前還有很多不完善之處,許多新技術正在研發之中。因此,蛋白質組學的發展是受技術限制的,也是受技術推動的。
如果說未知世界是一個無邊無際的海洋,那麼我們的知識就是這海洋里一個小小的島嶼。隨著科學的進步,知識的島嶼會不斷地擴張。但我們同時會發現,環繞著知識島的未知領域也在增長。我們的研究可以逐漸地擴大人類知識的領地,但永遠不能窮盡宇宙的奧秘。基因組也好,蛋白質組也好,都不會是人類認識生命的終點。
2001年的Science雜誌已把蛋白質組學列為六大研究熱點之一,其“熱度”僅次於幹細胞研究,名列第二。蛋白質組學的受關注程度如今已令人刮目相看。

人類蛋白質組計劃
雖然第一次提出蛋白質組概念是在1994年,但相關研究可以追溯到上世紀90年代中期甚至更早,尤其是80年代初,在基因組計劃提出之前,就有人提出過類似的蛋白質組計劃,當時稱為Human Protein Index計劃,旨在分析細胞內的所有蛋白質。但由於種種原因,這一計劃被擱淺。90年代初期,各種技術已比較成熟,在這樣的背景下,經過各國科學家的討論,才提出蛋白質組這一概念。
國際上蛋白質組研究進展十分迅速,不論基礎理論還是技術方法,都在不斷進步和完善。相當多種細胞的蛋白質組資料庫已經建立,相應的國際網際網路站也層出不窮。1996年,澳大利亞建立了世界上第一個蛋白質組研究中心:Australia Proteome Analysis Facility ( APAF )。丹麥、加拿大、日本也先後成立了蛋白質組研究中心。在美國,各大藥廠和公司在巨大財力的支持下,也紛紛加入蛋白質組的研究陣容。去年在瑞士成立的GeneProt公司,是由以蛋白質組資料庫“SWISSPROT”著稱的蛋白質組研究人員成立的,以應用蛋白質組技術開發新藥物靶標為目的,建立了配備有上百台質譜儀的高通量技術平台。而當年提出Human Protein Index 的美國科學家Normsn G. Anderson也成立了類似的蛋白質組學公司,繼續其多年未實現的夢想。2001年4月,在美國成立了國際人類蛋白質組研究組織(Human Proteome Organization, HUPO),隨後歐洲、亞太地區都成立了區域性蛋白質組研究組織,試圖通過合作的方式,融合各方面的力量,完成人類蛋白質組計劃(Human Proteome Project)。
蛋白質組學雖然問世時間很短,但已經在研究細胞的增殖、分化、異常轉化、腫瘤形成等方面進行了有力的探索,涉及到白血病、乳腺癌、結腸癌、膀胱癌、前列腺癌、肺癌、腎癌和神經母細胞瘤等,鑒定了一批腫瘤相關蛋白,為腫瘤的早期診斷、葯靶的發現、療效判斷和預后提供了重要依據。
鑒於蛋白質組學發展前景的重要性和技術的先進性,西方各主要發達國家紛紛投巨資全面啟動蛋白質組的研究。如美國國立衛生研究院,美國能源部、歐共體等均啟動了不同生物蛋白質組的研究並取得明顯進展,一批高質量的研究論文相繼在國際著名學術刊物發表。由於蛋白質組學研究比基因組學研究更接近實用,有著巨大的市場前景,企業與製藥公司也紛紛斥巨資開展蛋白質組研究。獨立完成人類基因組測序的Celera公司已宣布投資上億美元於此領域;日內瓦蛋白質組公司與布魯克質譜儀製造公司聯合成立了國際上最大的蛋白質組研究中心。為了促進國家與地區性的蛋白質組的發展、合作與交流,成立了國際人類蛋白質組組織 (HUPO),在法國召開了首屆國際蛋白質組大會,並迅即在北美、歐洲、韓國、日本成立了相應的分支機構。蛋白質組學已成為西方各主要發達國家、各跨國製藥集團競相投入的“熱點”。
要找出一個生物體基因組的所有基因和相應的全部蛋白質,是一項非常困難的任務。
不同生物的基因組大小有著很大的差別。例如芽殖酵母基因組有1200萬鹼基對,而人類基因組則為32億鹼基對。基因組不論大小,其核苷酸的數量總是很明確的。然而,對蛋白質組來說,蛋白質的種類究竟有多少就很難說了。上面說過,蛋白質組可以被定義為基因組的基因表達的所有蛋白質,但這一定義沒有考慮蛋白質的化學修飾。細胞內的大部分蛋白質通常在合成結束后,都被進行過化學基團的修飾,如磷酸化、糖基化、醯基化等等。修飾過的蛋白質的物理化學性質和生物學功能,均不同於未修飾的蛋白質。如果把一個修飾蛋白視為一種新的蛋白質,那麼蛋白質組的蛋白質數量,將遠遠大於相應的基因組的基因數量。在這個意義上,人們估計人類蛋白質組的蛋白質種類大約在20萬到200萬之間。顯而易見,蛋白質組蛋白質數量的估計是非常模糊的。
從蛋白質修飾的角度來看,不僅僅是蛋白質種類大大增加,更重要的是,由於不存在度量修飾蛋白質種類的尺度,人們也許永遠不能像確定基因組核苷酸序列那樣,準確地統計出生物體內蛋白質組的蛋白質總數。如果說表達產生的蛋白質種類可以根據基因的數目來確定,那麼修飾形成的蛋白質種類只有依靠對蛋白質的直接研究來判定。生命是一個永遠處於變化中的開放系統。既然蛋白質的修飾和生命活動密切相關,因而這種研究是沒有止境的。從這種意義上來說,對基因組核苷酸序列的測定是一種“有限”的工作,而對蛋白質組蛋白質種類的確定則是一種“無限”的工作。
DNA作為遺傳信息的載體,以雙螺旋的形式存在於細胞核內,在細胞一代代的繁衍過程中其鹼基序列始終保持不變,因此在測定基因組的DNA序列時不需要考慮時空的影響。而在蛋白質組的研究中,時間和空間的影響都是不可忽略的。
首先,在個體發育的不同階段或細胞的不同活動時期,細胞內產生的蛋白質種類是不一樣的。此外,不同蛋白質的壽命也不一樣。有些蛋白質在合成后成為細胞的結構成分,相當穩定;而有些蛋白質在產生后被用來進行某種細胞活動,比如基因轉錄的調控,工作一旦完成就被迅速降解。因此,在分析蛋白質組的蛋白質成分時,需要把時間作為一個重要的參數。對於在不同時間過程中蛋白質組的組成成分的比較分析——差異蛋白質組研究,已成為當前蛋白質組學的主要內容。
蛋白質的另一個重要特徵是,不同的蛋白質通常分佈在細胞的不同部位,它們的功能與其空間定位密切相關。要想真正了解蛋白質的功能,通常還需要知道蛋白質所處的空間位置。更為重要的是,許多蛋白質在細胞里不是靜止不動的,它們在細胞里常常通過在不同亞細胞環境里的運動發揮作用。例如細胞周期的調控過程、細胞的信號轉導和轉錄調控,都依賴於蛋白質空間位置的變化和運動。因此,蛋白質組學中又派生了一個與空間緊密相關的新研究領域——亞細胞蛋白質組學。這種亞細胞蛋白質組可能是細胞器蛋白質組,如高爾基體蛋白質組;也可能是比細胞器還要小的組分,如核膜的蛋白質組。
在不了解基因組序列的情況下,人們曾經推測,生命的複雜程度是由基因組的基因數量來決定的。也就是說,生命的複雜程度越高,其基因組擁有的基因數目越大。但隨著各種生物的基因組全序列的測定,科學家們認識到情況並非如此。線蟲(C. elegans)是一種低等動物,其基因組的基因數為1.9萬多個。而人類基因組框架圖的完成表明,人基因組的基因總數僅僅比線蟲多1.5萬個左右,遠不是預期的10萬到15萬。剛剛完成的水稻基因組框架圖更讓人吃驚,其基因總數在4.6萬到5.5萬之間,比人的基因還要多。顯然,基因數目與生命的複雜程度沒有直接的相關。那麼,在生命從簡單到複雜,從低級到高級的進化過程中,究竟是什麼因子體現了這種變化?
隨著功能基因組研究的進展,人們已逐漸意識到,這種因子可能就是不同基因的產物蛋白質之間“排列組合”的複雜程度。也就是說,原始生命體中蛋白質之間的相互關係比較簡單,而高級生命體中蛋白質之間則具有較為複雜的關係網。
蛋白質組具有一個不同於基因組的重要特性,即蛋白質彼此間有著直接的影響。某一個蛋白質功能的實現,通常離不開它與其他蛋白質之間的相互作用。也許可以說,不與其他蛋白質發生作用的“孤立蛋白質”根本就不存在。過去,科學家們因研究手段的限制,只能研究數個蛋白質之間的相互作用,而今天通過蛋白質組學的新方法,可以同時研究成千上萬個蛋白質之間的相互作用。例如,芽殖酵母基因組全部ORF的表達產物——共6000多個多肽,彼此間可能存在的作用情況已進行了分析,從中發現了9百多種可能的相互作用,涉及到1000多個蛋白質。科學家為這一類型的研究專門發明了一個新的名詞——“相互作用組”(interactomes)。
相互作用組研究可以分為兩類。第一類是研究蛋白質相互作用的網路。細胞內的許多活動如信號轉導等,都是通過一個複雜而廣泛的蛋白質相互作用網路實現的。相互作用組的另一類研究是蛋白質複合體組成的分析。蛋白質複合體通常可以分為兩種。一種是結構型的蛋白質複合體,如核孔複合體,這一類通常比較穩定?鴉另一種則是功能型蛋白質複合體,例如負責轉錄的轉錄蛋白複合體、負責DNA複製的複製蛋白複合體等,這類複合體只有在執行功能時才聚合在一起,任務完成後就解離。當前,相互作用組研究已成為蛋白質組研究領域的一個重要內容。
基因組的物質基礎是DNA,它由兩條螺旋狀生物大分子鏈組成,其中每一條鏈都由成千上萬的核苷酸連接而成,這些核苷酸僅含有四種類型的鹼基。基因組研究的核心任務,就是要測定DNA鏈上四種鹼基的排列順序。因此,DNA測序技術是基因組研究中一個最基本和最主要的工具,這樣一種單一的技術就能勝任基因組的研究工作。但是,在蛋白質組研究中,需要的研究技術遠遠不止一種,並且技術的難度也要大於基因組研究技術。
首先,由於蛋白質是由20種化學性質各異的氨基酸所組成,因此不同蛋白質的物理化學性質差別很大。例如,有些蛋白質易溶於極性溶劑,有些蛋白質則難溶於極性溶劑;有些蛋白質較穩定,有些蛋白質則易降解。此外,蛋白質的各種修飾和相互作用更增加了蛋白質的複雜性。僅僅通過一兩種技術,顯然不可能完成對蛋白質組內成千上萬種不同性質的蛋白質的檢測。
其次,不同種類的蛋白質的量在細胞內有著很大的差別。例如在酵母細胞里,有些細胞周期調控蛋白不到100個分子,而糖基酶則可能有200萬個分子。據估計,蛋白質之間量的差別,竟可達106數量級。蛋白質組研究的特點是要同時分析各種各樣的蛋白質,因此需要排除巨量的蛋白質類型的干擾,把微量的蛋白質類型從蛋白質混合物中鑒定出來。現有的蛋白質組研究技術,尚不能令人滿意地完成這一任務。
簡而言之,蛋白質組研究對技術的依賴性和要求遠遠超過
早期蛋白質組學的研究範圍主要是指蛋白質的表達模式(Expression profile),隨著學科的發展,蛋白質組學的研究範圍也在不斷完善和擴充。蛋白質翻譯后修飾研究已成為蛋白質組研究中的重要部分和巨大挑戰。蛋白質-蛋白質相互作用的研究也已被納入蛋白質組學的研究範疇。而蛋白質高級結構的解析即傳統的結構生物學,雖也有人試圖將其納入蛋白質組學研究範圍,但目前仍獨樹一幟。
可以利用一維電泳和二維電泳並結合Western等技術,利用蛋白質晶元和抗體晶元及免疫共沉澱等技術對蛋白質進行鑒定研究。
很多mRNA表達產生的蛋白質要經歷翻譯后修飾如磷酸化,糖基化,酶原激活等。翻譯后修飾是蛋白質調節功能的重要方式,因此對蛋白質翻譯后修飾的研究對闡明蛋白質的功能具有重要作用。
如分析酶活性和確定酶底物,細胞因子的生物分析/配基-受體結合分析。可以利用基因敲除和反義技術分析基因表達產物-蛋白質的功能。另外對蛋白質表達出來后在細胞內的定位研究也在一定程度上有助於蛋白質功能的了解。Clontech的熒光蛋白表達系統就是研究蛋白質在細胞內定位的一個很好的工具。
對人類而言,蛋白質組學的研究最終要服務於人類的健康,主要指促進分子醫學的發展。如尋找藥物的靶分子。很多藥物本身就是蛋白質,而很多藥物的靶分子也是蛋白質。藥物也可以干預蛋白質-蛋白質相互作用。
在基礎醫學和疾病機理研究中,了解人不同發育、生長期和不同生理、病理條件下及不同細胞類型的基因表達的特點具有特別重要的意義。這些研究可能找到直接與特定生理或病理狀態相關的分子,進一步為設計作用於特定靶分子的藥物奠定基礎。
蛋白質組學的發展既是技術所推動的也是受技術限制的。蛋白質組學研究成功與否,很大程度上取決於其技術方法水平的高低。蛋白質研究技術遠比基因技術複雜和困難。不僅氨基酸殘基種類遠多於核苷酸殘基(20/4), 而且蛋白質有著複雜的翻譯后修飾,如磷酸化和糖基化等,給分離和分析蛋白質帶來很多困難。此外,通過表達載體進行蛋白質的體外擴增和純化也並非易事,從而難以製備大量的蛋白質。蛋白質組學的興起對技術有了新的需求和挑戰。蛋白質組的研究實質上是在細胞水平上對蛋白質進行大規模的平行分離和分析,往往要同時處理成千上萬種蛋白質。因此,發展高通量、高靈敏度、高準確性的研究技術平台是現在乃至相當一段時間內蛋白質組學研究中的主要任務。當前在國際蛋白質組研究技術平台的技術基礎和發展趨勢有以下幾個方面:

蛋白質組研究設備

蛋白質組研究工作台

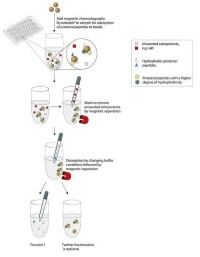
蛋白質組研究技術
蛋白質組資料庫是蛋白質組研究水平的標誌和基礎。瑞士的SWISS-PROT擁有目前世界上最大,種類最多的蛋白質組資料庫。丹麥、英國、美國等也都建立了各具特色的蛋白質組資料庫。生物信息學的發展已給蛋白質組研究提供了更方便有效的計算機分析軟體;特別值得注意的是蛋白質質譜鑒定軟體和演演算法發展迅速,如SWISS-PROT、Rockefeller大學、BHS寶護神、UCSF等都有自主的搜索軟體和數據管理系統。最近發展的質譜數據直接搜尋基因組資料庫使得質譜數據可直接進行基因註釋、判斷複雜的拼接方式。隨著基因組學的迅速推進,會給蛋白質組研究提供更多更全的資料庫。另外,對肽序列標記的從頭測序軟體也十分引人注目。
在基礎研究方面,近兩年來蛋白質組研究技術已被應用到各種生命科學領域,如細胞生物學、神經生物學等。在研究對象上,覆蓋了原核微生物、真核微生物、植物和動物等範圍,涉及到各種重要的生物學現象,如信號轉導、細胞分化、蛋白質摺疊等等。在未來的發展中,蛋白質組學的研究領域將更加廣泛。
在應用研究方面,蛋白質組學將成為尋找疾病分子標記和藥物靶標最有效的方法之一。在對癌症、早老性痴獃等人類重大疾病的臨床診斷和治療方面蛋白質組技術也有十分誘人的前景,目前國際上許多大型藥物公司正投入大量的人力和物力進行蛋白質組學方面的應用性研究。
在技術發展方面,蛋白質組學的研究方法將出現多種技術並存,各有優勢和局限的特點,而難以象基因組研究一樣形成比較一致的方法。除了發展新方法外,更強調各種方法間的整合和互補,以適應不同蛋白質的不同特徵。另外,蛋白質組學與其它學科的交叉也將日益顯著和重要,這種交叉是新技術新方法的活水之源,特別是,蛋白質組學與其它大規模科學如基因組學,生物信息學等領域的交叉,所呈現出的系統生物學(System Biology)研究模式,將成為未來生命科學最令人激動的新前沿。