終止密碼子
不編碼任何氨基酸的密碼子
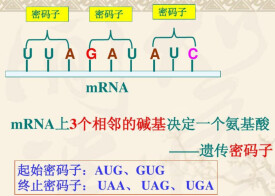
密碼子UAA,UAG和UGA並不編碼任何氨基酸,因此,也稱為無義密碼子( nonsensecodon)但這個名稱並不恰當,因為它們雖然不編碼任何氨基酸,卻起著終止肽鏈合成的作用,因此,稱為終止密碼子( termination codon)。UAA也稱為赭石型( ochre),UAG稱為琥珀型( amber),UGA稱為乳白型(opal)密碼子。所有這3個密碼子均是作為肽鏈終止的密碼子,它們在蛋白質合成中起著終止肽鏈延長的作用。有兩個釋放因子RF1和RF2,它們分別識別2個終止密碼子:RF1識別UAA和UAG,RF2識別UAA和UGA。RF1和RF2均是蛋白質,這便表明,多核苷酸不僅可以和另一種多核苷酸相互作用,也可以和蛋白質起相互作用;也即是說,不僅鹼基與鹼基之間可以生成氫鍵而互相識別,也可以和蛋白質中的氨基酸生成氫鍵而被識別。
直到1965年Weigert,M.和Ggaren,A由鹼性磷酸酶基因中色氨酸位點的氨基酸的置換證明E.coli中無義密碼子的鹼基組成揭示了琥珀和赭石(ochre)突變基因分別是終止密碼子UAG和UAA。當時64個密碼中的61個已破譯,只留下了UAA、UAG 和UGA有待確定。Garen等為了鑒定無義密碼子採用了和Brenner相似的策略。他們從E.coli的鹼性磷酸酯酶基因 (pho A)中的一個無義突變品系中分離了大量的回復突變株,然後來探察每一個無義突變中在多肽中相當於已回復的無義密碼子位置上的氨基酸究竟是什麼氨基酸。可以看出無義密碼子是從該基因的色氨酸位點的密碼子產生的。在回復突變中,無義密碼子變成了Trp、Ser、Tyr、Leu、Glu、Gln和Lys的相應密碼子。僅有Trp的UGG變成UAG,然後在此基礎上回復突變成7種氨基酸,因此Trp 產生的無義突變的密碼子就是UAG。最後1967年Brennr和Crick證明UGA是第三個無義密碼子。根據無義突變的三種昵稱,三個終止密碼子UAA叫赭石(ochre)密碼子(相應於赭石突變);UAG叫琥珀密碼子(相應於琥珀突變);UGA叫蛋白石(opal)密碼子(相應於蛋白石突變)。
1964年Yanofsky在研究E.coli色氨酸合成酶A蛋白時推測無義密碼子的存在。他的推測/是從兩個不同的角度:一是為trpA編碼的mRNA還編碼了trpB,trpC,trpD和trpE。即一個mRNA分子中可以作為不同多肽的模板,那麼有可能在翻譯時中途在某個位點(兩個肽的連接處〕停止,然後再從下一個新的起點翻譯,這樣使各個肽可以分開,而不至於產生一條很長的肽鏈。這就意味著終止密碼子的存在。另一個角度是他發現E.coliTrp-的突變株是不能合成完整的色氨酸合成酶蛋白,但繼續對它進行誘變可以得到回復突變。回復突變中有兩種,一種是個別發生了變化,而另一種是完全回復,沒有任何氨基酸組成的變化,這表明,E.coliTrp-不可能是任何移碼突變的結果,那麼這類的突變很可能攜帶有阻止合成的無義密碼子。
1962年Benzer和他的學生S.Champe對T4rⅡ突變的研究時發現野生型的T4rⅡ這段有兩個順反子rⅡA和rⅡB,共同轉錄一個多順反子mRNA,但翻譯成兩個分開的蛋白A和B。當發生缺失突變時,其中有一個突變型為rl589,證明是缺失所造成,缺失的區域含rⅡA基因右邊的大部分,和rⅡB左邊的小部分。互補實驗表明rl589的產物是一條多肽,但無蛋白A的活性,但有B蛋白的活性。Benzer認為,這種缺失可能使mRNA失去了A蛋白合成“終止”和“B”蛋白合成“起始”的密碼子,因此翻譯時沿著一條mRNA閱讀下去,產生了一條長的肽鏈。
1964年Brenner及其同事獲得了T4噬菌體編碼頭部蛋白基因的琥珀突變(amber),並進行了精細作圖,並分離研究了各種突變型的多肽。突變型的肽鏈比野生型的要短,因此可以推測琥珀突變可能產生終止密碼子,使肽的合成在中途停止下來;由於突變位點越靠近基因的左端,所產生的肽鏈越短,越靠近右端越接近野生型,據此可以推測翻譯的過程是從mRNA的5’端向3’閱讀。肽鏈的合成是從N端向C端延伸。
由於頭部蛋白80%是由新合成的蛋白質組成。因此他們將各種突變型及野生型T4噬菌體侵染E.coli后10分鐘,把14C標記的氨基酸加到培養基中,過一段時間,從感染的E.coli中抽提蛋白,頭部蛋白可以通過14C標記來加以鑒別。
基本信息
- 中文名
- 終止密碼子
- 時間
- 1962年
- 琥珀突變
- amber
- 終止密碼子
- UAG,UAA,UGA