知識引擎
知識引擎
知識引擎來源於Knowledge engine。一種智能化的漢語知識管理系統。利用這一系統,企業可以將分散在各部門乃至各位員工腦中的知識、技能、訣竅、規則、價格、政策、經驗等各類信息組合成一個具有本企業全面知識的、虛擬的超級客戶服務專家。
史蒂芬·沃爾弗拉姆希望避開網頁搜索,而是通過計算來回答用戶的在線查詢,所有資源都來自於公司的資料庫。2009年5月15日,他在伊利諾伊州的控制中心發布了他的“知識引擎”Wolfram Alpha。想要知道玉米麵包中含有多少膽固醇和飽和脂肪,你需要將黃色的索引卡上標出的成分輸入到在線查詢框中,Alpha將會開始計算並給出一個美國農業部官方風格的營養標籤。Wofram研究院的創建人之一西奧多·格雷(Theodore Gray)說:“當然,你也可以使用谷歌,尋找出標準雞蛋中的熱量等等,但這是多麼痛苦呀!你需要數據,並且需要那些已經根據需要轉換好單位的數據,然後你要把他們加起來。你可以像幾十年前一樣去做,到圖書館找到參考文獻,現在你可以通過谷歌或者其他搜索引擎開始查找,但我們使這變得更為簡單了。”他補充道:“使用傳統的搜索引擎,輸入‘加入一杯糖,一磅麵粉’,它會給出滿屏無用的信息。”
這只是可以反映Alpha是做哪一類事情的一個例子:對特定的一類問題,首先通過一個有限集合,提供更深入、精確並且更圖像化的答案。搜索“D# 大調”將會給出音樂譜線圖,搜索“金星”將得到詳細的當天夜空圖,搜索成對的公司名將得到兩公司的對比圖表。它也會增加一些額外信息:搜索“紐約,倫敦,距離”不僅可以得到按照公里、英里和海里計量的距離數值,還有一張標出飛行路線的地圖,並有噴氣式飛機、聲波和光束完成這一行程耗時的對比。詢問某個字(以word開頭)將會得到詞源學的表格和同義詞網路等。
為了完成這類工作,它運用數學、科學數據集合和已經嵌入到Mathematica中的一些公式,完成答案的組建。對於一些新的信息,如政府食品數據,僅需少量的重新整合,這也正是威廉目前正在做的。其他的,如實時股票價格,則需要執照。另外的信息,如飛機航班數據,則需要從一些公開的網路資源如維基百科、Freebase中收集,經整理后得出。
沃爾弗拉姆本人卻正在波士頓,準備次日下午的首次公眾演示(他已經給萬維網創始人提姆·伯納-李(Tim Berners-Lee)和其他技術界領袖,包括微軟的比爾·蓋茨、谷歌的謝爾蓋·布林和亞馬遜的傑夫·貝索斯在內的人們演示過)。我坐在格雷的辦公室里,這裡更像是一個元素周期表的世界而非工作間:鎳、鉻、硒、硫磺等將近一打樣本裝飾著玻璃架子。(他自豪的打開一個鉛盒,拿出一個昏暗的大約兩包撲克牌大的金屬板,那是11磅重的非濃縮鈾,但仍有一定的放射性。)格雷說:“目前只能搜索基於文本的現有素材,這種想法是有局限性的,代表了想象力的一種失敗。”
Wolfram Alpha起初範圍有限,只擁有一個有些死板用戶界面和模糊的信息來源,但公司合夥創建人(素材收集者)西奧多·格雷表示,目前主要的搜索引擎正遭受“大量假的幻想信息”的困擾,並且計算能力非常差。
大廳的另一側,身為宇航員和MathWorld(目前由Wolfram主持的一種在線參考服務)創始人的埃里克·魏爾斯史甸(Eric Weisstein)正坐在辦公室的吊蘭植物和蠟紙杯之間(這可以有效地凈化空氣,他解釋到),將一個複雜的單位轉換器中已經完成轉換的內容輸入到Alpha中來檢驗結果。魏爾斯史甸說:“如果你搜索網頁,不說上千,至少也得有上百個網頁可以完成英尺到米的轉換。但他們不夠靈活,不夠權威,大多數情況下覆蓋面也不足。”
這種計算並不能告訴你一杯牛奶或者一杯麵粉中有多少克(答案因物質而不同),更不用說用它們來轉換1“捏”(對於鹽來講,是380毫克)或者1“滴”(如果是穀物油,1“標準滴”是56毫克)或者1“大桶”(相當於很多的酒,重248千克),還有更少見的導熱係數單位,男士帽國際通用大小單位,或者任何種類的蒲式耳。魏爾斯史甸說:“蒲式耳很重要,1蒲式耳大豆和1蒲式耳小麥是不一樣的,也和1蒲式耳容積不同,更別提1蒲式耳質量了。我們已經建成了世界上最好的單位換算器!”
在整座建築和一些遠程的分部里,大約有150名Wolfram員工以相似的方式工作著。在艾得·佩格(Ed Pegg)的工作間里找到他,他正沉浸在瓷磚的課題中。他手邊是一些權威的參考資料,700頁的由Grünbaum和謝潑德(Shephard)寫的瓷磚與樣式,詳細描述了人行道磚塊的箭尾型和籃筐紋路材料的晶體學樣式。
還有更多的花樣:伊斯蘭瓷磚樣式(八邊形、六邊形、兩種星型);由九邊網狀楔形組成的雙螺旋;基於各種五角型的14種樣式。儘管瓷磚的資料不會在引擎發布之前載入使用,佩格仍然創造了樣式的組合和計算方法。使用這些工具,圖案設計者就可以創造出埃舍爾樣式(例如使用交互的鮮花,而非雜色金絲雀);化學家就可以探究一系列分子如何互相組合;家庭主婦則能夠想象出一個新的浴室地板樣式。
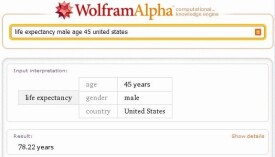
2009年4月27日晚,暴雨拍打著傑米·威廉(Jamie Williams)隔間旁的小窗。這位物理學家坐了下來,筋疲力盡,卻仍沉浸在食品科學的種種細節中。他面前的屏幕顯示了一張來自美國農業部的原始數據表格,包含了從黑莓到牛肉等7000種食物的相關數據。他和一個四人的團隊正在“審查”這些數據,為一種新的在線搜索做準備。
他梳理那些標識了150種屬性(營養成分,熱量,碳水化合物等等)的標籤,保證各種縮寫保持一致,並被電腦識別。他將食物分組以便更有利於自然語言查詢。例如,搜索關於“牛奶”營養成分的信息將給出相關均值,而“脫脂乳”的搜索將給出特定的答案。
威廉並沒在矽谷的網路企業家的陣營中立足,而是在中西部的一座科學怪人的城堡里:伊利諾斯州香檳市的Wolfram研究院,它位於一座可以俯視華爾格林公司和麥當勞的辦公大樓中。這也是史蒂芬·沃爾弗拉姆(Stephen Wolfram)的“藏身處”。沃爾弗拉姆是一位物理學家,數學軟體Mathematica的發明人,這款軟體是面向數學家、科學工作者和工程師們的一款通用的、最為完整的、技術與圖形化軟體。
威廉正在致力於一項被公司稱作“計算知識引擎”的工作:Wolfram Alpha。對於提出的問題,Alpha計算出答案而並非僅僅列出網頁。它包括三個部分,一個在香檳市人工維護的不斷擴展的資料庫,一個精心製作的計算器,和一個用於查詢的自然語言界面。
1993年,馬里蘭大學一位剛畢業的俄羅斯學生來到Wolfram研究院實習,他非常聰明並對計算機充滿興趣,在Mathematica軟體的核心方面做了一些實際工作。隨後,他離開研究院前往斯坦福大學拿到了自己的碩士學位,並和他人一起創建了谷歌。如今,谷歌要處理約64%全美國的搜索。但是,從前的那個Wolfram實習生瑟吉·布因(Sergey Brin)並不是很開心。他統領了一個產業,身價120億美金,在瑞士達沃斯的世界經濟論壇年會上叱吒風雲。
搜索技術並沒跟上他的個人提升的步伐。“我仍然希望,我們能夠在更多重要領域取得進展。”布因在谷歌2008年度報告中寫到:“完美的搜索需要近乎和人一樣的智能,許多人仍然覺得這很遙遠。然而,我相信,很快我們就會擁有一個搜索引擎,可以比今天的那些更多地理解我們的需求和文件的要求。有人聲稱已經可以做到這點,谷歌的後台系統也已經比外觀部分更智能,但整個業界仍然因不能達到我希望的成果而感到羞愧。”
在網路搜索的一些主要領導角色中――從Excite(已破產)到Alta Vista(2003年被雅虎收購)到如今的頂尖五玩家(谷歌,雅虎,微軟,Ask和AOL)――其核心方法仍然相同。他們創建大量的網頁索引,即他們的軟體為了找到最匹配的查詢結果,將不斷“爬滿”數十億計的網頁,收集短語、關鍵字、標題和鏈接。
谷歌的成功之處在於它排列網頁的方法,部分基於對鏈接之間結構的分析來產生較優的結果。雖然網頁在過去的十年中已經翻了10000倍,但搜索引擎在找到相應答案並進行智能組合方面仍未取得相應的進步。語義學網頁――一個期待已久的系統,其中的信息被標記並可以進行上述處理――仍然是遙遙無期。
2008年,雅虎發布了“搜索猴子”(SearchMonkey),讓網頁發布者通過增加標籤來使搜索引擎軟體提高搜索質量,如“這是個地址”、“這是個電話號碼”等等。(所以現在,如果你在雅虎上搜素一個飯店的地址,你可能不僅得到該飯店網頁的連接,還會列有該飯店地址,電話號碼的宣傳單,還有一系列編輯好的評論。)雅虎實驗室主管普拉巴卡爾·格海文(Prabhakar Raghavan)說:“‘搜索猴子’所做的就是,發掘了語義學網頁的潛力並將它公佈於眾以便發布者可以參與進去。”谷歌最近也開始研究相似的技術,並稱其為“豐富片段”(rich snippets)。
即使由伯納·李(Berners-Lee)領導的國際標準制定實體——世界萬維網協會(World Wide Web Consortium,W3C)--已經制定了一系列措施,來促進推廣語義學網頁,但這個想法仍在網際網路上傳播緩慢。位於阿姆斯特丹的領導著世界萬維網協會語義學研究的伊凡·赫爾曼(Ivan Herman)表示,即使世界萬維網協會的標準被廣泛採用,他們也不能在計算上有太多指導性。他說:“數據、數值計算和數學處理如何結合起來,仍然沒有明確的定義,這當然是我們需要展開工作的領域。”
雖然目前的搜索引擎正逐步推廣,並向新的領域擴張(地圖、照片、視頻、新聞),學習回答簡單問題(“紐約的人口是多少?”),甚至進行簡單的轉換(“10英鎊等於多少千克?”),但它們並不深入和高效。華盛頓大學計算機科學家和語義學網頁研究員丹尼爾·威爾德(Daniel Weld)說:“雖然谷歌很棒,但我更願意使用企業號飛船上那樣的計算機,你可以對其詢問一些高層次的問題,它會給出答案並加以解釋,然後你可以提問說‘為什麼你認為這是對的?’它就會給你答案的出處。”
當史蒂芬·沃爾弗拉姆看到這點時,他正在組建以真正智能的方式回答提問的基礎構架――儘管起初只是偏向於一些怪異領域。他說:“我們無需面對網站普遍存在的員工變遷問題,我們咬牙堅持:‘讓我們自己來處理這些數據吧!’如果語義學網頁已經存在,而我們僅需要收集數據,那就太棒了!那會是完美的結合,但事實不是這樣。”
在香檳附近的新數據中心裡,演出主角史蒂芬·沃爾弗拉姆確認了兩台超級計算機由藍綠兩個LED燈點亮,並為自己建立了略高的指揮部。他已經安排了網上直播。2009年5月15日晚上10:30,暴風預警覆蓋了伊力諾依州大部,他用滑鼠點擊了“開始”的按鈕,隨後,安裝在牆上的大屏幕顯示了計算機群迅速啟動並運行。他說:“從統計的角度講,肯定會出現一些差錯,問題是故障究竟是什麼。”儘管有一些電壓波動和早期超級計算機曾出現過載,沃爾弗拉姆還是避免了類似Cuil公布時出現的系統崩潰。
他的引擎本身也面臨著性能上的巨大問題。儘管當它“知道”一些事情時,它的表現是那麼完美而優雅,但是當有更多的未知擺在面前時,(並且很難猜測出它知道什麼),Wolfram Alpha網頁經常出現對你的輸入不確定去做什麼的情況,這主要因為它組織好的數據間存在著巨大的空隙。Alpha是一個圖書館,而那些書架卻只是部分被填充,在歷史、政治、文化、體育、社會科學和流行文化方面仍是空白。網站本身也受一個缺乏靈活性的自然語言界面的困擾。
例如,你搜索“艾薩克·牛頓生日”,你會得到牛頓的生日(1642年12月25日;你也會知道那天月亮正處在由新月向滿月的變化階段)。但如果你輸入“艾薩克·牛頓出生”,Alpha就會卡住。阿倫森和我測試了它,發現它不能回答“誰發明了網際網路?”並且不知道各州的國民生產總值,只有一些國家層次的數據。但它能夠解決任何數學問題,包括地球表面積是多少。阿倫森查詢“愛爾蘭的國民生產總值除以42的餘弦是多少?”得到了一個對數坐標下的使用從1970年到2007年相關生產總值數據進行相關計算的表格。
最後,是一些標註上的問題。點擊鏈接可以得到各種資源:中央情報局的世界概況、“科學史上的今天”的網頁、美國地質勘測調查、道瓊斯指數、和物種目錄(一個國際維護全球已知物種的索引),但並沒有指明哪個資源提供了哪項事實。(格雷表示,公司正在努力工作,增加這類對特定的事實和計算結果進行標註的標籤。)
但如果你給Wolfram Alpha足夠的寬容,也就是你詢問它所了解的項目和它理解的一些使用過的搜索詞,並且不關心最初的來源,它會表現得翔實、智能、並有著驚人的圖形效果。對物質的搜索會給出化合物組成圖,對天體的搜索會給出夜空圖(視角是根據你的計算機的IP地址對應的地理位置而定)。它可以做普通人都想做的(例如產生定製的營養標籤)和那些只有極客(geek:智力超群善於鑽研行為方式特立的人)關心的事情(如由布爾代數等式產生一系列真值表)。
加州伯克利大學的計算機科學家馬蒂·赫斯特(Marti Hearst)告訴我:“Wolfram Alpha在搜索技術上是巨大的進步,它提高了人們對那些存儲在資料庫中的內容應該如何搜索的期望。”赫斯特是《搜索用戶界面》一書的作者,但她補充道,它距“完成偉大目標還有很長的路要走。”
搜餅:對於那些它可以處理的問題――尤其是在數學、科學和工程方面的計算問題――Wolfram Alpha使用了許多原創的技巧。給出煎餅成分后(1),引擎就給出了許多可能選項(2),給出如何解釋輸入內容(3),然後就能得到一個綜合營養標籤(4)。在這些場景的背後,Wolfram的Mathematica軟體首先進行了必要的單位轉換(例如,將“一撮鹽”轉換成“380毫克鹽”),但提供的“信息來源”(5)並沒追蹤具體的參考來源。
沃爾弗拉姆聲稱,他們會繼續努力,其中的一些問題可以通過增加更多的數據來解決。為了改進處理過程,網站包含了人們提交個人事實、整體的結構化數據集、甚至演演算法和模型的鏈接。不像維基百科――那裡增加和編輯信息是免費開放的,只有一些團體提供彼此相互的制衡――Wolfram Alpha計劃保持一個更加集中的管制方式,即它的“專家管理團隊”將在數據添加至資料庫前進行檢驗。
但有些人認為,沒有自動的或者共享驅動的處理過程,在不對網頁進行類似搜索引擎一樣的索引下,擴展數據將非常困難。華盛頓大學的威爾德說:“在某些方面,如果沒有原始數據的驅使,計算就不會那麼有用了。谷歌平方很符合趨勢,可能贏得這場比賽。”
事實上,即使承認他的引擎仍然只是雛形,一些懷疑者仍質疑Wolfram的方法是否比一些特定的應用程序更見效。網際網路協會的伊凡·赫爾曼說:“儘管我是數學家出身,對數學的東西懷著極大的敬意,但我仍不確定是否可以通過數學公式和計算來解決這世界上的所有不幸。”諾維格回應了這番言論:“這裡某些的數據集合是適用於某些方法的。如果你要討論金的原子量,如果不同的實驗室都在研究,他們可能關注小數點后的5或6位,但誰在乎呢?”
諾維格說:“許多事情的意見無法統一,它要取決於數據是什麼,你要做怎樣的計算。但對於非數值的數據,做哪種運算就顯得不很明確了。”威爾德又補充道:“設想一個問題,‘誰是最危險的恐怖分子?’這個問題很難,有人是恐怖分子么?我們怎麼衡量危險程度?對誰來講是危險的?計算是很難對這種問題做出解答的。”
在某些情況下,Wolfram對計算的沉溺卻能對某些特定用戶產生比只想市場佔有率的公司提供更好的服務,那些公司很自然地對幫助大眾找到更好的搜索結果感興趣,那是他們已經在做的。雅虎的瑞格海文說:“例如,在評估散布在多家網站的某個旅館時,給出一個簡要的等級評價更符合用戶意圖,而不是關注於他們想要東歐巴爾幹半島國家人口總和。總會有人提出神秘的問題,但我們必須專註於滿足99%的用戶要求。”
開張兩周,Wolfram Alpha已經處理了10億次詢問,並收到了55000次反饋,表明了人們對更深層次解答的興趣。沃爾弗拉姆說:“Wolfram Alpha將要做的,是,讓人們能夠將科學與工程的成果應用到日常生活中,正如網路和搜索引擎已經使數十億人成為參考資料管理員一樣。”一個火狐瀏覽器的插件已經發布,使得搜索者在谷歌搜索結果旁邊顯示Alpha結果。沃爾弗拉姆表示,他的引擎將會不斷升級。發布后的三周,他就宣布了第一次對代碼和數據的大範圍升級,包括了對自然語言界面的改進、增加了更多附屬國家(如威爾士)的數據、搜索特定時間的股票價格的功能,“尤其增加了更多澳洲的數據。”
沃爾弗拉姆說,,在20年間對Mathematica開發上投資了數十億美金之上,他已經在Wolfram Alpha上投入了數千萬美金。搜索結果的旁邊已經開始出現廣告,他也計劃提供帶有更多功能的專業定製版本。程序介面(稱做API)使得開發人員可以構建使用WolframAlpha搜索的應用程序。他告訴我:“我們會看到這究竟是一項慈善事業嘗試還是商業。”
2009年4月28日下午3點,離發布還有兩周的時間,49歲的沃爾弗拉姆站到了哈佛法學院的講台。他有著灰白色頭髮,略現禿頂,一臉緊張神情。他衣著樸實,像往常一樣穿著一件土黃色牛津大學襯衫、卡其褲子、和耐克運動鞋。他首次向公眾(網路播放)展示Wolfram Alpha。操著一口柔軟的英國口音,他很快簡介了引擎的一些技巧,例如鍵入字元Gs,Cs,As和Ts來得到DNA序列里出現的鹼基詳細數據。
過去20年間,沃爾弗拉姆已經因他的才智和極端自信而出名。作為一個出生在倫敦的天才,他跳過了本科學位,直接從加州理工學院拿到了物理學博士學位,當時他才20歲,兩年之後,他獲得了麥克阿瑟基金會“傑出人物”獎。他在加州理工、普林斯頓高級研究院、和伊利諾伊大學都有傑出的成就。但在20世紀80年代中葉,他離開了學術領域,組建了Wolfram研究院。1988年,公司發布了第一版Mathematica軟體。該軟體包含了豐富的數學函數庫和在二維、三維顯示數據的圖形化工具,並有著翔實的資料庫,囊括了宇宙天體、化學化合物、次原子微粒、社會經濟學事件、金融證券、人類基因及蛋白質、和一些簡單的生平傳記等信息。它提供了很好的可視化工具:集合形狀,分子圖,軌道描繪。
第一版Mathematica軟體發布14年之後――期間他並沒有公布任何研究成果――Wolfram出版了一本1200頁的書,《一種新的科學》(A New Kind of Science),之後常稱其為NKS。書中,他假定了許多複雜系統和問題――從動植物分類學到量子力學――都可以簡化成簡單的規則。在《紐約時報》上,喬治·約翰遜(George Johnson)聲稱,“沒有人在看待世界的方法上帶來如此巨大的影響。”但沃爾弗拉姆的自我評價——這本書“已經被看作是科學歷史上重要的模範式變革的起步”――卻吸引的不止是眼球。麻省理工學院計算機科學家斯科特·阿倫森(Scott Aaronson)說:“形容詞 Wolframian已經進入到詞典,意思是將每個人都知道的事情展示出來,並看作是現實自然界的重要發現。”阿倫森並不否認Mathematica是一個很“酷”的軟體,但他認為,NKS雖然作為通俗科學上有價值,但卻“對我所了解的計算機科學和物理領域本質上沒有影響。”
對於沃爾弗拉姆來講,Alpha融入NKS成為了人類科學的勇敢探索之一。他曾經發布過一張兩頁的列表,將Alpha放在了以算數與書面語言的發明為開始,逐步到亞歷山大圖書館,牛頓和大英百科全書的創建這一整段歷史的最後。他將Mathematica定位在1989年網際網路發明之前;NKS位於維基百科和Web2.0之間,而把最後一段的 Wolfram Alpha表述成:“定義了一種新的基於知識的計算。”對Alpha的重要性的實際驗證,部分來自於沃爾弗拉姆在哈佛法學院的演講。在下午3:17分,谷歌的官方博客公布了一項新的服務,允許人們搜索並比較一些公共數據,包括聯邦人口統計和勞動力數據。這項服務不僅返回網頁鏈接,而且會有谷歌自己繪製的圖表。(例如搜索“俄亥俄州失業率”,將會得到一張數據圖表和一些用來和其他州失業率比較的方法。)博客聲稱,它開創了允許鍵入各種領域的“感興趣的公共數據”的新方法,包括“餅乾的價格、二氧化碳的排放量、氣喘發病率、高中生畢業率、麵包師的工資、野火發生的數目和其他一些項目”。
谷歌自從收購了圖像技術公司Trendalyzer開始,已經開發此項業務兩年之久。公司表示,發布的時機完全是巧合。但很明顯,這個產業巨頭也同沃爾弗拉姆和他的同事們一樣,也意識到了網頁搜索的不足。兩周之後,Wolfram發布的前夜,谷歌在“搜索學”技術會上,宣布了另外一項數據決策服務,谷歌平方(Google Squared)。這項技術在谷歌實驗室網站上可以使用,能將來自不同的網路資源組合,並打包成漂亮的表格。例如,搜索“過山車”,可以得到從亞瑟王神劍到Montezooma的復仇等美國主要娛樂公園的一張表格,表格的每列有拇指大小的照片,描述了過山車的高度、長度。用戶可以點擊結果,來刪除原始表格中的錯誤,並修改搜索結果。谷歌副主席瑪瑞莎·邁耶(Marissa Mayer)在會議中表示,谷歌平方“給搜索指引了全新的方向”。她補充道:“將雜亂的信息組織起來並結構化地展示是計算機科學上的難題。”
谷歌表示他們將在搜索結果中提供更好的實時數據。如果你搜索“舊金山大地震”,谷歌和Alpha相似,都將會從美國地理調查中挑選出最新的相關報告。(這點和航班、或比賽比分的實時數據相同)谷歌研究主管皮特·諾維格(Peter Norvig)告訴我,這項技術代表了公司在搜索、組合和數據展示方面的努力前景。“總之,我想說,我們的方法將更加面向開放系統,而非封閉的、被引導的系統。”諾維格還說:“但我真的很欣賞Wolfram Alpha提供的更包容的用戶界面和數據分析工具。我們想更進一步,也許和他一決雌雄將激勵我們更多更快地研發軟體。”
搜索引擎Ask的技術執行副主席斯科特·金姆(Scott Kim)更直接地認為,Wolfram將會產生一定影響。他提到Alpha時說:“我認為,它開闊了人們的視野,普通公眾的視野,讓人們知道可以從計算引擎中得到些什麼,它是怎樣集成到搜索引擎當中的。這絕對是未來搜索的一部分,但仍有很長的路要走。”
基本信息
- 外文名
- Wolfram Alpha