水稻基因組計劃
水稻基因組計劃
1998年由中國內陸以及台灣地區與日本、美國、法國、韓國、印度等發起,多國共同完成的對水稻基因研究的國際科研工程。1997年9月,水稻基因組測序國際聯盟在新加坡舉行的植物分子學大會期間成立。1998年2月,中、日、美、英、韓五國代表制定了“國際水稻基因組測序計劃”,2002年12月12日,中國科學院、國家科技部、國家發展計劃委員會和國家自然基金會聯合舉行新聞發布會,宣布中國水稻基因組“精細圖”已經完成。水稻基因組計劃研究包括水稻基因組測序和水稻基因組信息,是繼“人類基因組計劃”后的又一重大國際合作的基因組研究項目。

水稻
水稻是最重要的糧食作物之一,直接關係到世界一半人口的生活質量。而決定水稻品質與產量的,則是水稻的基因。
1993年,基因中心以中國主要栽培品種秈稻廣陸4號為水稻基因組研究品系。1996年,中國在國際上率先完成了水稻(秈稻)基因組物理圖的構建。更為有價值的是,韓斌研究組在測序4號染色體的同時,還對另一個亞種秈稻廣陸矮4號染色體序列進行了測定,通過對兩個品種連續長度達230萬個DNA鹼基對相應序列的同源比較,首次報道了水稻兩個主要栽培稻(秈稻、粳稻)間的基因組成、順序及DNA基因水平上的一些異同,從而揭示了栽培稻間的一些親緣關係和進化關係。這是中國科學家在水稻基因研究領域的獨到貢獻。《自然》審稿人認為:這些數據為將來整個基因水平上的比較提供了一個良好的示範。
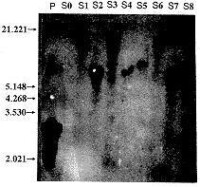
水稻基因組
1998年,國際水稻基因組測序計劃正式啟動,中國以及台灣地區與日本、美國、法國、韓國、印度等一道,成為這一國際組織的成員。每個國家根據自身的經濟實力,除日本承擔6條染色體的測序外,其它國家與地區大都只承擔一條染色體的測序。根據國際水稻基因組織的協議,其成員必須將測序的所得數據提供給公共基因庫,同時,也可以分享他人的數據,和有關這一領域的先進技術與成果。這就意味著,中國水稻基因的測序研究,奉獻了10%的工作量,卻擁有了分享另外90%成果的資格基因中心已向公共資料庫遞交了超過5000萬鹼基的水稻基因組DNA序列數據。日本在水稻基因研究領域處於領先地位,而中國的第4號染色體與日本的第1號染色體工作同時刊出論文,這本身就是國際合作的結果。
在測序過程中,需要大量的探針,中國暫不具備成熟的產品。而日本從1992年就開始研究,探針的技術與產品已相當完備和成熟。根據協議,國家基因研究中心因此獲得了最好的探針,提高了測序的準確性。
2002年12月18日,國際水稻基因組測序工程結束紀念儀式在東京舉行,200多位來自10個國家和地區的科學家和日本各界代表出席了會議。宣布國際水稻基因組測序結束。

水稻基因組研究八大發現
水稻基因組研究八大發現
據專家介紹,中國“水稻(秈稻)工作框架序列圖”與人類、擬南芥等已經測定的基因組序列相比,主要有八大發現:
1 估計水稻基因組中基因總數在46022至55615之間,其基因總數幾乎是人類基因組基因總數的兩倍;
2 水稻基因主要通過基因加倍而使“基因家族”的成員數目增加,但每一“成員”的功能比較單一;
3 基因頭尾差別大,大部分水稻基因的頭部與尾部組成不一樣,增加了基因發現的難度;
4 水稻、擬南芥與人類基因組都有很多不編碼蛋白質的“垃圾”序列。水稻的這些“垃圾”序列多位於基因之外,而人類的卻在基因之內。正因為如此,水稻基因的平均長度只有4500個鹼基,而人類基因的平均長度為72000個鹼基;
5 擬南芥已發現有2.5萬個基因,80%左右的基因在水稻的基因組中都可找到。而水稻基因組中只有一半不到的基因在擬南芥基因組中找到;
6 秈稻與粳稻的基因組有1/6不一樣;
7 水稻序列的相互之間差異近1%,而人類序列的相互差異為1‰左右;
8 秈稻與雜交水稻母本的序列給雜交水稻的機制提供了新的啟示:“雜交優勢”很可能與基因組大小、基因表達等都有關係。

水稻基因組計劃
國際水稻基因組計劃破譯了水稻遺傳的“密碼本”,科學家可以根據測序得到的精確序列,對水稻中影響產量、口感、香味、抗病蟲害等重要農業性狀的基因進行鑒定,並採取措施提高水稻的產量和質量。這些將給水稻育種帶來革命性的影響。
國際水稻基因組計劃的完成,在農業生產上的意義可以與人類基因組計劃對人類健康的意義相媲美。獲得水稻基因4號染色體的序列分析結果,將有助於了解小麥、玉米等其它禾本科農作物的基因組,為培育具有高產、優質、抗病蟲害、抗逆等優良性狀的水稻新品種打下良好基礎。
基因研究對水稻研究的影響是多方面的。比如以前人們水稻選種只能依靠目測,而通過基因研究,人們可以利用遺傳途徑改良水稻品種,水稻的選種時間也可以大大縮短。
水稻基因數目再次表明,生命的複雜性遠遠超乎人類的任何預先設計和想象,而任何一次科學進步,都將使人類更加接近真理,接近事物的真相。正如人類基因數曾經出現過的波折那樣:最開始人們認為大概有3萬到10萬個,直到2000年人類基因組工作框架圖被繪製並“解讀”后,人們才發現人類的基因只有3萬到4萬個,遠遠低於最開始的推測。
基因組測序涉及DNA的大規模測序,由於目前只能採取分而治之的測序基本策略,即將基因組DNA分割成一定大小的片段,然後分別對這些片段進行測序。而遺傳圖和物理圖可作為整個基因組測序的路標,為小片段DNA測序和重疊群構建提供了基礎。
水稻基因組計劃
水稻基因組計劃
由於YAC克隆不太穩定、插入DNA難以分離、轉化效率低等原因,美國Clemson大學基因組研究所(ClemsonUniversityGenomicsInstitute,CUGI)又建成了兩個BAC庫,一個是由37000個HindⅢ酶切的BAC文庫,插入片段平均長度為128.5kb;另一個是有56000個克隆的EcoRⅠBAC庫,插入片段平均大小為120kb,兩者覆蓋水稻基因組的26倍。1997年,中國科學院國家基因研究中心(NationalCenterforGeneResearch,NCGR)發表了由指紋?錨標法策略建成的含565個分子標記且覆蓋率較高的水稻廣陸矮4號基因組BAC庫物理圖。
2001年,RGP為了克服YAC克隆的局限性,又以PAC為載體構建了水稻Nipponbare基因組文庫,此文庫由72000個Sau3AⅠ酶切克隆組成,平均插入片段長120kb,覆蓋水稻基因組的16倍。RGP也對75000個PAC克隆進行了排列,所有已定位的可用標記用於鑒定和錨定PAC克隆。這些克隆分成3個池,以EST衍生的特異引物進行PCR排序,一個EST共有的幾個PAC克隆被認為是重疊的,它們歸為一個克隆群,這個方法可以解除由於雜交探針屬於多基因家族而帶來的困難。

染色體
微生物基因組
粳稻是適宜於溫帶地區種植的另一類栽培稻亞種,秈稻和粳稻兩個亞種大約於200~300萬年前在進化中產生分離,兩者不同的基因組比例達22%以上。日本晴(Nipponbare)基因組框架圖,共完成550萬個成功反應,得到了42109個重疊群,覆蓋深度大於6×;覆蓋率為93%;非冗餘序列為389809244bp,鹼基準確率大於99.99%,GC含量達44%;預測基因數為3.2~5.0萬個,拷貝基因占基因總數的77%;轉位因子4220個,簡單重複序列數為46666個;參照擬南芥的功能分類法,從抗病性、花時和花發育特性、新陳代謝、磷的轉運子和轉錄因子等方面進行了基因功能分類(圖1)。這套粳稻基因組框架圖被簡稱為Syd(Syngentadraftsequence。
蛋白質組
第10染色體的預測長度達23.7Mb。已經以99.99%的精度完成了大約22422563bp的測序工作,短臂和長臂分別為7.6Mb和14.8Mb。共預測到3471個基因和67個tRNA編碼基因,其中,8.3%基因與EST相匹配。51.4%基因的功能已被分類。G C含量達43.5%。這些序列貯存在美國的DNA公共資料庫中(GenBank),記錄代碼為AE016959。
水稻基因組的成功測序是繼完成人類基因組測序后的又一巨大成功。它必將成為禾穀類作物基因組研究的里程碑。
水稻基因組測序的完成及2002年9月中國水稻功能基因組計劃(ChinaRiceFunctionalGenomicsProgram,CRFGP)的啟動,這一切都具有劃時代的意義。然而,這還只是初步完成了整個基因組學的第一步——結構基因組學,水稻全基因組的完成圖和第二步的功能基因組學的路更長,且更具現實意義。
生物信息學
大量微生物和模式生物的基因組全序列測序完成,如線蟲(Caenorhabditiselegans)、釀酒酵母(Saccharomycescerevisiae)、擬南芥(Arabidopsisthaliana)、果蠅(Drosophilamelanogaster)和水稻(Oryzasativa)等。完成基因組測序僅僅是基因組計劃的第一步,更大的挑戰在於弄清:⑴基因組順序中所包含的全部遺傳信息是什麼。⑵基因組作為一個整體如何行使其功能。也即“后基因組計劃”,又稱為功能基因組學。水稻的基因總數有可能在5萬~6萬個左右,至今已報道的功能基因只有20%。隨著被克隆基因的日益增多,對基因功能的研究顯得日益迫切。一系列研究基因功能的方法湧現,如基因轉導技術、基因敲除技術、基因嵌入技術及突變體庫篩選和全基因組表達分析。可以不同規模地鑒定出各類參與細胞新陳代謝、轉錄、信號轉導、運輸和植物防禦等功能基因。數以十萬計的基因及其編碼的蛋白質可供基因工程和蛋白質工程的操作,從而大大擴展生物技術的產業範圍。
蛋白質的結構是其功能的基礎,翻譯后修飾是蛋白質調節功能的重要方式,蛋白質與DNA或蛋白質的相互作用及其調節是細胞中信號傳導及所有代謝活動的基礎。蛋白質組學的主要技術包括二維聚丙烯醯胺凝膠電泳、質譜分析、蛋白晶元、酵母雙雜交系統和噬菌體展示技術。已有一系列有關水稻不同組織和器官中蛋白質組研究的報道,從根、莖、葉片、種子芽、糠和愈傷組織中分離蛋白質,經二維聚丙烯醯胺凝膠電泳,總共分辨出4892個蛋白斑點,其中約3%的氨基端序列已被測定;從根的蛋白中檢測到292個斑點,其中76種蛋白的氨基端及內部序列已經測定,根據氨基酸系列,在水稻cDNA文庫中經同源性搜索找到編碼42種蛋白的cDNA克隆,如果文庫足夠大,那麼編碼蛋白的所有cDNA均應較容易地通過計算機搜索鑒定出來。

水稻基因組計劃在水稻改良上的應用研究
生物信息學的主要研究內容是生物資料庫及生物信息分析,隨著各種模式生物基因組計劃的實施,生物資料庫數量持續增長,資料庫結構更複雜,大量新的分析方法被提出和改進,大量重要基因被發現;大量來自基因組水平上的分析比較結果被公布,這些結果正在日益改變人類已有的一些觀念。各種資料庫中具有生物聯繫的內容能連接到一起,實現生物信息資源共享。DNA資料庫是公共生物資料庫中最大的一類資料庫,包含大量已知功能和未知功能的DNA系列。中國水稻功能基因組項目也構建了一個綜合的水稻基因信息資料庫,包含了國內外相關的水稻插入突變體、TAC末端序列和ESTs序列,可為進一步研究新基因的功能提供更多有價值的信息。生物信息學已廣泛用於基因組和蛋白質組的研究,但是,隨著大多數基因和蛋白質功能的闡明,將會出現一個新的發展前景,這就是在計算機上模擬細胞內部和機體內部的生化代謝過程,甚至模擬進化 的歷程,這將使生物學真正進入理論生物學的新時期。
傳統水稻育種的成功主要依賴於一系列優異基因(如矮稈基因、抗病和細胞質雄性不育基因)的發掘和利用,功能基因組發現的新基因也將大大促進水稻新品種的選育。通過水稻基因組序列比較分析和多態性鑒定,發現了品種之間的序列差異,而這些差異與表型差異一致。重要的是,利用這些差異將為分子標記輔助育種提供一個前所未有的機會。5萬~6萬個左右水稻基因的功能註釋完成以後,對植物界有普遍意義。已利用遺傳工程將單個或多個目的基因導入水稻栽培品種,改良作物某些性狀。科學家們可以利用“分子設計育種”,只要在屏幕上觸摸任何發育階段的水稻細胞就能看到所有表達的蛋白質以及它們之間的相互作用,在電腦上制定出“保護水稻整個生命周期一切活動所需的最佳基因”研究方案。

基本信息
- 中文名
- 水稻基因組計劃
- 外文名
- Oryza sativa L
- 提出時間
- 1998年
- 提出單位
- 中國內陸